- Published on
vRealize Automation
- Authors
- Name
- Jackson Chen
vRealize Suite Documentation
https://docs.vmware.com/en/vRealize-Suite/index.html
VMware vRealize Automation Documentation
https://docs.vmware.com/en/vRealize-Automation/index.html
Administering vRealize Automation
Administering vRealize Automation
vRealize Automation 8.6 Reference Architecture Guide
vRealize Automation 8.6 Reference Architecture Guide
Preparing and Using Service Blueprints in vRealize Automation 7.6
Preparing and Using Service Blueprints in vRealize Automation 7.6
Installing and Configuring vRealize Orchestrator
Install and configure vRealize Orchestrator 7.6
Install vRealize Automation with vRealize Easy Installer
Install vRealize Automation with vRealize Easy Installer
Getting Start with vRealize Automation Cloud Assembly
Getting Start with vRealize Automation Cloud Assembly
Using and Managing vRealize Automation Cloud Assembly
Using and Managing vRealize Automation Cloud Assembly
Using and Managing vRealize Automation Code Stream
Using and Managing vRealize Automation Code Stream
Using and Managing vRealize Automation Service Broker
Using and Managing vRealize Automation Service Broker
Install and Configure SaltStack Config
Install and Configure SaltStack Config
Using and Managing SaltStack Config
Using and Managing SaltStack Config
Using and Managing SaltStack Security Operations
Using and Managing SaltStack Security Operations
vRealize Automation integration with provider-specific IPAM
vRA integration with provider-specific IPAM
vRealize Automation Load Balancing Guide
vRealize Automation Load Balancing Guide
vRealize Orchestrator Load Balancing Guide
VMware vRealize Orchestrator 8.x Load Balancing Guide
vSphere with Tanzu
vRealize Automation 8.4 API Programming Guide
https://developer.vmware.com/docs/13520/vrealize-automation-8-4-api-programming-guide
VMware Cloud Foundation Documentation
https://docs.vmware.com/en/VMware-Cloud-Foundation/index.html
VMware Cloud Foundation API Reference Guide
https://developer.vmware.com/apis/1181/vmware-cloud-foundation
SaltStack Config
https://docs.saltproject.io/en/latest/
https://www.vmware.com/au/products/vrealize-automation/saltstack-config.html
https://docs.vmware.com/en/VMware-vRealize-Automation-SaltStack-Config/index.html
Helm - Package Manager for Kubernetes
Ansible Documentation
YAML
Helm
References sites
YAML 1.2 reference parser
Online YAML Parser
http://yaml-online-parser.appspot.com/
Amazon Web Service Documentations
Azure Documentation
https://docs.microsoft.com/en-gb/documentation/
https://docs.microsoft.com/en-us/azure
Terraform registry
https://registry.terraform.io/
Terraform Language Documentation
https://www.terraform.io/docs/language/index.html
Terraform CLI documentation
https://www.terraform.io/docs/cli/index.html
VMware Tanzu Kubernetes Grid Integrated Edition Documentation
https://docs.vmware.com/en/VMware-Tanzu-Kubernetes-Grid-Integrated-Edition/index.html
VMware Tanzu
https://tanzu.vmware.com/tanzu
vRealize Automation
vRealize Automation is a platform that automates the delivery of virtual machines, applications, and personalized IT services across a multivendor, multicloud infrastructure. vRealize Automation delivers self-service automation, DevOps for infrastructure, Kubernetes automation, configuration management, and network automation. You can integrate, and modernize traditional, cloud-native, and multicloud infrastructures with vRealize Automation. It offers a common Service Catalog for administrators, developers, and business users to request IT services, including infrastructure, applications, and desktops.
The key components are Cloud Assembly, Service Broker, Code Stream and vRealize Orchestrator.
Cloud Assembly
The primary purpose of Cloud Assembly is to create and deploy VMware Cloud Templates.
VMware Cloud Templates are the specifications that define the machines, applications, and services that you create on cloud resources through Cloud Assembly. VMware Cloud Templates are previously called blueprints.
Cloud Assembly administrators configure the infrastructure to support the development and deployment of VMware Cloud Templates.
Project members use Cloud Assembly to iteratively develop and deploy VMware Cloud Templates.
vCenter Server, VMware Cloud Foundation, Amazon AWS, Microsoft Azure, and Google Cloud Platform are some of the cloud accounts supported by Cloud Assembly. Users can create VMware Cloud Templates as code in the YAML format, and they can download VMware Cloud Templates from VMware Marketplace.
Service Broker
Service Broker aggregates services from multiple sources into a single catalog, users use this catalog to request the offered services.
As a cloud administrator, you create one of the following catalog items
# Templates and services
1. VMware Cloud Template
2. AWS Cloud Formation Template
3. Marketplace VM Templates - OVA
4. vRealize Automation Code Stream pipeline
5. Extensibility action
6. vRealize Orchestrator workflow
# Using policies and constraints
1. Lease # Ensure duration of the service provided
2. Day 2 Actions # Such as update, and normal daily operations on the VM or service
3. Approval # Ensure approval when requested catalog meet or reach certain conditions.
vRealize Automation Code Stream
vRealize Automation Code Stream provides the Continuous Integration and Continuous Delivery (CICD) capability that enables you to deliver the software rapidly and reliably. It integrates with Git, Jeakins, Bamboo, Code Stream build, Jira, email, Kubernetes and docker, that running on multiple clouds.
You can create a pipeline that runs actions to build, deploy, test, and release your software. vRealize Automation Code Stream runs your software through each stage of the pipeline until it is ready to be released to production. You can integrate your pipeline with one or more DevOps tools, such as data sources, repositories, or notification systems, which provide data for the pipeline to run.
vRealize Orchestrator
vRealize Orchestrator is a development and process-automation platform that provides an extensive library of workflows and a workflow engine.
vRealize Orchestrator simplifies and automates complex data center infrastructure processes by using workflows. A workflow is a program that describes a sequence of tasks that achieve a specific function. You can use the vRealize Orchestrator prebuilt workflows or easily design new workflows to automate IT processes across VMware and third-party applications.
vRealize Automation Cloud
vRealize Automation Cloud is the web-based SaaS version of vRealize Automation. VMware Cloud services offers vRealize Automation Cloud.
vRealize Cloud Universal License
vRealize Cloud Universal is a hybrid subscription bundle of both on-premises and SaaS vRealize Suite products. It is available in three editions. This new subscription model offers the flexibility to deploy vRealize components on-premises or consume vRealize services as SaaS interchangeably without the need to repurchase licenses.
vRealize Automation Deployment Architecture
There are two deployment architectures.
1. Standard deployment - Small environment
The standard deployment includes three appliances.
a. vRealize Suite Lifecycle Manager
b. VMware Identity Manager (aka VMware Workspace ONE Access)
c. vRealize Automation
vRealize Lifecycle Manager is deployed first, then vRealize Identity Manager, and vRealize Automation.
2. Clustered deployment - Large environment & Producation
a. vRealize Lifecycle Manager
b. Load Balancer which load balancing one or three VMware Identity Managers appliances
c. Load Balancer which load balancing three clustered vRealize Automation appliances
Requirements:
a. Certificate generated and pre-configured
b. Load Balancer pre-configured
vRealize Lifecycle Manager is used to deploy, upgrade, configure and manage the vRealize Suite productions.
VMware Identity Manager
VMware Identity Manager provides multifactor authentication, conditional access, and single sign-on to Saas, web and native mobile apps. VMware uses VMware Identity Manager as an enterprise SSO solution.
vRealize Automation appliance
vRealize Automation appliance is powered by Photon OS, it includes native Kubernetes to host containerized services.
1. All the core vRealize Automation services run as Kubernetes pods.
2. RabbitMQ is the industry standard message bus used in vRA. RebbitMQ runs as a pod.
3. PostgreSQL is the default and the only supported database for vRA.
4. PostgreSQL runs a pod and uses Persistent volume (PV) to store data.
A Persistent Volume might represent a host path (/mnt/data) or an iSCSI, NFS volume.
# vRA start up process
1. Appliance is powered on
2. Docker is installed, and K8s clusters are configured during the first boot
3. Helm takes images from private registry and deploy pods
4. vRA services run as Docker containters in K8s pods.
Note:
a. A pod is the smallest deployable unit in K8s.
b. The docker engine hosts the containers in a pod.
A Kubernetes service is an abstraction that defines a logical set of pods and a policy by which to access them (sometimes this pattern is called a microservice).
Each Kubernetes pod hosts one or more containers.
For example, the vRealize Orchestrator service runs as a pod hosting the following key containers:
1. Control Center is used to manage the operation of vRealize Orchestrator, including plug-ins.
2. The vco-server service is the orchestration engine responsible for running workflows.
The databases run as a pod managed by Kubernetes whose data is stored in a persistent storage volume.
Namespaces are a way to divide Kubernetes cluster resources between multiple users.
Helm
Helm is the package manager for Kubernetes. Helm is used to package, configure, and deploy applications and services onto Kubernetes clusters. Service configurations are stored in the Kubernetes native Helm package manager format called charts. A chart describes a service in vRealize Automation: its containers, number of instances, network settings, persistence, and so on, and is stored in a human-readable text format.
vRealize Easy Installer
vRealize Easy Installer simplifies this installation process through a single installation wizard that installs and configures vRealize Lifecycle Manager, VMware Identity Manager and vRealize Automation.
vRealize Easy Installer ISO can be mounted on Linux, MacOS and Windows.
# vRealize Easy installer process
1. Download the vRealize Easy Installer ISO
2. Mount the ISO and run the executable
a. Select Install # Install new implementation
b. Migrate # Migrate data from earlier versoin of Lifecycle Manager to the current instance
3. vRealize Suite Lifecycle Manager is deployed and configured
4. vRealize Lifecycle Manager installs vIDM
5. vRealize Lifecycle Manager install vRA
6. vRA is configured and all the services are running
vRealize Lifecycle Manager direct migration will migrate the following data:
a. Data centers and vCenter Server systems
b. All existing environments
c. DNS, SNMP, NTP, My VMware, and proxy details
d. VMware Identity Manager installation or import
e. Blackstone content endpoints
Note:
Blackstone content can no be migrated.
vRealize Easy Installer splits the configuration into two sections
- Common Configuration
# Common configuration
1. Appliance Deployment Target
# Target vCenter Server with administrator credential
2. Select a Location
# Target data center or VM folder
3. Select a compute Resoure
# Target compute resource, vSphere cluster
4. Select a Storage Location
# Target datastore and enable thin provisioning
5. Network Configuration
# Common network settings, network subnet, gateway, DNS servers, domain name, and NTP servers
6. Password Configuration
# Common password
- Application specific configuration
# Appliance specific configurations
1. Lifecycle Manager Configuration
a. Data Center Name
Define a data center name in vRealize Suite Lifecycle Manager to group multiple vCenter Server systems.
b. vCenter name
The name defined for the target vCenter Server system used in vRealize Suite Lifecycle Manager.
c. Increase Disk Size in GB, Extra disk space defined to increase during installer run.
d. FIPS Mode Compliance: Enable or disable the FIPS mode. When FIPS is enabled,
inbound and outbound network traffic on port 443 uses encryption.
2. Identity Manager Configuration
- Skip idm
- Install New vIDM
- Import Existing vIDM
a. Default Configuration Admin # configadmin
b. Default Configuration Email # configadmin@<email-domain>
c. Node Size # Medium, Large, Extra Large, and Extra Extra Large
d. Sync Group Members to the Directory When Adding Group
# Enable group members syncrhonization
3. vRealize Automation Configuration
a. vRA Environment name
The name for the vRealize Automation environment in vRealize Suite Lifecycle Manager.
b. FIPS Mode Compliance (Enable or disable the FIPS mode)
When FIPS is enabled, inbound and outbound network traffic on port 443 uses FIPS-compliant encryption.
c. Node Size (Medium and Extra Large)
Kubernetes clusters pods and services CIDR (classless inter-domain routing) network settings
Note
i. Default: 10.244.0.0/24 and 10.244.4.0/24
ii. The networks are used by pods as internal networks
The following password are configured during the appliance configuration
1. vRealize Lifecycle Manager
a. root password
b. admin password
- Default: admin@local
2. vIDM
a. admin password
b. sshuser password
c. root password
d. password for default configuration user that is used when integrating products
3. vRA
a. root password
Complex password with min 8 characters and max 16 characters.
vRealize Lifecycle Manager Environments
An environment is a logical entity that includes one or more vRealize products
# vRealize Suite Lifecycle Manager creates the following environments:
1. Global environment for deploying and managing VMware Identity Manager
2. vRealize Automation environment
Note: The name of the vRealize Automation environment is the name specified in the vRealize Easy Installer wizard.
vRealize Automation - Quickstart
After the installation, you log in to the vRealize Automation console as the Default Configuration Admin user specified during installation.
# vRA access URL
https://<vRA_FQDN>
You can use the Quickstart wizard to set up your on-premises software-defined data center (SDDC) for provisioning with vRealize Automation, populate the self-service catalog, and deploy your first VMware Cloud template.
The following options are available in the Quickstart wizard:
1. Add or select a vCenter Server account and an associated NSX Manager instance.
Then set up your SDDC for provisioning with vRealize Automation and populate the self-service catalog.
2. Add an integration to SDDC Manager and create a cloud account for a VMware Cloud Foundation workload domain.
Then set up your SDDC for provisioning with vRealize Automation and populate the self-service catalog.
vRealize Automation Migration Assistant
vRealize Automation Migration Assistant facilitates the migration from vRealize Automation 7.x to 8.x.
# The migration from vRealize Automation 7.x to 8.x is performed in the following sequence:
1. Define a source vRealize Automation 7.x instance.
2. Perform a migration assessment against your source to determine the migration readiness of your vRealize Automation 7.x source environment.
The migration assessment alerts you to any system object and its dependencies that are not ready for migration and that impacts your migration process.
3. After performing a migration assessment,
you can migrate to import content and configuration data from your current vRealize Automation 7.x source environment to vRealize Automation 8.3.
a. Migrate the infrastructure
b. Migrate the subscriptions
c. Migrate the deployments
Authentication and Authorization
vRealize Automation requires
1. an authentication to allow user login, and
2. authorization to assign a set of privileges
VMware Identity Manager
VMware Identity Manager is used to manage user authentication, access policies, and entitle users to resources. Administrators can use access policies to configure features, such as mobile single sign-on (SSO), conditional access to applications based on enrollment and compliance status, and multifactor authentication.
# Access URL
https://<vIDM-FQDN>/saas/admin
Note:
VMware Identity Manager is based on the OAuth 2.0 authorization framework.
The identity service runs as a pod in Kubernetes.
pod name: identity-app
database name: identity-db
Note: It is a dedicated PostgreSQL database
Directory Integration
You integrate your enterprise directory with VMware Identity Manager to sync users and groups from your enterprise directory to the VMware Identity Manager service.
# The following types of directories are supported:
1. Active Directory over LDAP
a. Create this directory type if you plan to connect to a single Active Directory domain environment.
b. The connector binds to Active Directory by using simple bind authentication.
2. Active Directory, Integrated Windows Authentication
a. Create this directory type if you plan to connect to a multidomain or multiforest Active Directory environment.
b. The connector binds to Active Directory by using Integrated Windows Authentication.
Important Note:
The prerequisite for using the Integrated Windows Authentication option is to add the VMware Identity Manager appliance to the domain.
3. OpenLDAP directory
a. You can only integrate a single-domain OpenLDAP directory.
b. VMware Identity Manager supports only those OpenLDAP implementations that support paged search queries.
Note:
a. The vIDM system directory is created by default, and
b. The configuration admin user is created in the system directory.
Mapping User Attributes
Select the attributes that are synchronized between Active Directory and VMware Identity Manager.
# Important configuration note:
When you configure the User Attributes page before the directory is created
a. you can change default attributes from required to not required,
Such as mark "email" from required to not required
b. mark attributes as required, and
c. add custom attributes
# How to change the required user attributes
1. Navigate to the Identity & Access Management tab
2. click Setup -> User Attributes
Synchronizing Groups
Specify the groups that you want to sync from Active Directory to the VMware Identity Manager directory. After you integrate your enterprise directory and perform the initial sync, you can update the configuration, set up a sync schedule to sync regularly, or start a sync at any time.
Note:
The Sync nested group members check box is selected by default.
Features of VMware Identity Manager
VMware Identity Manager includes these additional features
1. Access policies
2. Support for multiple user authentication methods
3. Two-factor authentication
4. Password recovery assistant
5. Just-in-Time user provisioning
vRealize Automation Console
Log in to the vRealize Automation console as the Default Configuration Admin user. This user has access to all three tabs with full administrative access.
Login URL: https://<vRA-FQDN>
# Three tabs
1. Services
# Under section - My Services
a. Cloud Assembly
b. Code Stream
c. Orchestrator
d. Service Broker
e. vRA Migration Assessment
2. Identity & Access Management
3. Branding
Note:
The vRA organization name is editable.
# How to change organizatoin Name
1. Navigate to and select the top-right "Config Admin" icon
2. From drop down, select Organization Setting
3. Click View Organization
4. Click Edit at Organization Name
Note:
One vRealize Automation deployment can have only one organization.
Branding - How to change vRealize header name and logo
The default header name and logo can be customized from the Branding tab.
vRealize Automation Roles
In vRealize Automation, roles are broadly categorized into
1. Organization roles
# Organization roles are defined at the top most vRealize Automation layer
a. Organization Owner
i. Can access all three tabs - Services, Identity & Access Management, Branding
ii. Assign roles to Active Directory groups and users
Note:
The key responsibility of an organization owner is to assign roles.
b. Organization Member
i. Can only access Service tab
ii. Key role is to create cloud templates and deploy cloud templates
2. Service roles
# Service roles define user access to individual services offered by vRealize Automation
# Each of the following service also has its own service roles
a. Cloud Assembly
i. Cloud Assembly Administrator
ii. Cloud Assembly User
b. Code Stream
i. Code Stream Administrator
ii. Code Stream User
iii. Code Stream Viewer <-------- Only available in code stream
iv. Code Stream Executor <-------- Only available in code stream
c. vRealize Orchestrator
i. vRealize Orchestrator Administrator
ii. vRealize Orchestrator User
d. Service Broker
i. Service Broker Administrator
ii. Service Broker User
Note:
Only one organization can exist in a vRealize Automation deployment.
We can also create custom user roles with vRealize Automation. Roles can be assigned to users or groups.
# How to assign roles to users or groups
1. Navigate to Identity & Access Management tab
2. Select either
a. Active Users
i. Edit the user, then assign an organization role
ii. Select the service, and service role
b. Enterprise Owners
i. Edit the group, then assign an organization role
ii. Select the service, and service role
Note:
1. We must assign roles to a group
2. We must associate an organization role with a service role
Service roles
The service roles are defined as follows
1. Cloud Assembly
a. Cloud Assembly Administrator
i. Create cloud accounts and cloud zone
ii. Create and manage projects
iii. Create and manage Flavor Mapping, and Image Mappings
iv. Create and manage Network and Storage Profiles
v. Create and manage tags
# tags enable cloud agnostic cloud templates
b. Cloud Assembly User
i. Create and manage cloud template
ii. Deploy machines and services
iii. Manage deployments
2. Code Stream
a. Code Stream User
i. Create and manage pipelines
ii. Create and manage endpoints
iii. Create and manage dashboards
b. Code Stream Administrator
i. All actions performed by user can be executed
ii. Resume pipelines that stop for an approval
Note:
- Mark an endpoint or variable as restricted
- Run pipelines that include restricted endpoints or variables
c. Code Stream Viewer
i. View piplelines, endpoints, and dashboards
ii. View pipeline executions
d. Code Stream Executor
i. All actions performed by viewer can be executed
ii. Run pipelines, rusume, pause, cancel pipeline executions.
3. vRealize Orchestrator
a. vRealize Orchestrator Administrator
i. Access to built-in workflows, actions, and policies
ii. Access to built-in packages, configurations, and resources
iii. Add Git Repositories (GitHub, GitLab)
b. vRealize Orchestrator User
i. Create new workflows, actions, and policies
ii. Import packages, configurations, and resources
4. Service Broker
a. Service Broker Administrator
i. Configure content source
ii. Configure policy definitions
iii. Add cloud accounts and cloud zones
b. Service Broker User
i. Access to self-service catalog
ii. Deploy machines and services
iii. Manage deploymnet
Multi-Tenancy and Virtual Private Zones
Multi-Tenancy
Multitenancy enables a single instance of vRealize Automation to be securely shared by multiple customers, also called tenants. Tenants can create their own projects, flavor mappings, image mappings, tags, deployments, and so on.
Configure DNS forward and reverse records and multi-tenancy certificates
The multitenancy configuration procedure is performed in vRealize Suite Lifecycle Manager.
# How to create multitenancy for vRA
1. Configure DNS records
a. vRealize systems DNS entries # defult tenant DNS records
vrlcm01 Host(A) 1.2.3.4
vidm01 Host(A) 1.2.3.5
vra01 Host(A) 1.2.3.6
b. default-tenant Host(A) 1.2.3.5 # vidm DNS entry
tenant1 Host(A) 1.2.3.5 # vidm DNS entry
tenant2 Host(A) 1.2.3.5 # vidm DNS entry
Note: Need to create Reverse DNS entries
c. tenant1-vra Alias(CNAME) 1.2.3.6 # vra DNS entry
tenant2-vra Alias(CNAME) 1.2.3.6 # vra DNS entry
Note:
Do NOT create the CNAME for the default tenant
2. Create multi-tenancy certificates
Import multi-tenancy certificates to vRealize Lifecycle Manager
a. Generate SSL certificate for
i. VMware Identity Manager
Note:
vIDM SSL certificate request -> Hostname/SAN name, need to include
- vidm01 FQDN
- default-tenant FQDN
- tenant1 FQDN
- tenant2 FQDN
- FQDNs of additional tenants
- vidm01 IP address
ii. vRealize Automation
Note:
vRA SSL certificate request -> Hostname/SAN name, need to include
- vra01 FQDN
- tenant1-vra FQDN
- tenant2-vra FQDN
- FQDNs of additional host
- vra01 IP address
Apply multi-tenancy certificates to VMware Identity Manager and vRealize Automation
1. Apply multi-tenancy certificates to VMware Identity Manager
Configure multi-tenancy certificates in VMware Identity Manager
Note:
Create snapshot for vIDM from vRealize Lifecycle Manager
b. Trigger Inventory Sync
i. Login to vRealize Lifecycle Manager
ii. Select Lifecycle Operations -> Environments
ii. Navigate to globalenvironment, click "...", select Trigger Inventory Sync
c. To replace the single-tenant certificate with the multi-tenancy certificate
i. Login to vRealize Lifecycle Manager
ii. Select Lifecycle Operations -> Environments
iii. Navigate to globalenvironment, click VIEW DETAILS
iv. In the pop up Window, click "..." vertical ellipsis icon and select Replace Certificate
2. Apply multi-tenancy certificates to vRealize Automation
Configure multi-tenancy certificates in vRealize Automation
Note:
Create snapshot for vRA from vRealize Lifecycle Manager
a. Login to vRealize Lifecycle Manager
b. Select Environment -> Manage Environments
c. Select vRealize Automation environment -> Trigger Inventory Sync -> Submit
d. Verify synchronization complettion
d. Navigatge to vRA environment, and click "..." ellipis icon, select Replace Certificate
e. Select newly created vRA certificate -> next -> Run Precheck -> Finish
f. Then follow the above steps to replace vRA SSL certificate
Enable multi-tenancy in vIDM
# Enable multi-tenancy in vIDM
1. Enable Tenancy in Lifecycle Manager
a. Login to vRealize Suite Lifecycle Manager
b. Select Identity and Tenant Management
c. Select Tenant Management -> Enable Tenancy
d. Click Trigger Inventory Reync -> Proceed
d. In Enable Tenancy in Identity Manager,
i. Select vRA environment
ii. In Master Tenant Alias, enter the default tenant -> Submit
2. Create New Tenants
a. In vRealize Lifecycle Manager
b. Select Identity and Tenant Management
c. Select Tenant Management -> Add Tenant
d. Enter new Tenant Name, and Administrator login credential and email ID
# Create new tenant in vRealize Lifecycle Manager
e. On product associations, select vRealize Automation -> Save and Next
f. Click Run Precheck -> Save and Next
g. Click Create Tenant
Note:
- You are prompted to take snaphot and perform inventory sync
- In the Master Tenant Alias text box, enter the name of the default tenant,
which is also called the provider organization, such as default-tenant.
Virtual Private Zones
A Virtual Private Zone (VPZ) is a type of container of infrastructure capacity and services, which can be defined and allocated to a tenant. The settings in each VPZ can only be changed by the Provider administrator, which is the default tenant administrator.
You can add unique or shared cloud accounts, with associated compute, storage, networking, and tags to each VPZ.
# Create Virtual Private Zone is performed in vRealize Automation
1. Login to default tenant vRealize Automation
2. Select Cloud Assembly
3. Navigate to Configure -> Virtual Private Zone
4. Click New Virtual Private Zone
5. In Summary section
a. Enter the name for the new VPZ
b. Select Account/region # Select the required cloud acount or region
c. Select Placement policy # or use Default
d. Capability tags # Enter capability tag(s) if any
6. In Compute section
a. Select Include all unassigned compute, or
b. Manually select computer, and select the required compute(s) under the could account/region, or
c. Dynamically include compute by tags
7. In Storage section
a. Select disk type
i. Standard disk, or First class disk (FCD) # Select Standard disk
b. Storage policy
# Select require storage policy, or use Datastore default
c. Datastore/cluster
d. Provisioning type
e. Shares
f. Limit IOPS
g. Disk mode
8. In Network section
# Select the required network
9. Click Save
10. Verify the newly created Virtual Private Zone has been successfully created.
vRealize Automation Basic Initial Configuration
You can configure vRealize Automation rapidly so that you can start creating and deploying VMware Cloud Templates.
You can set up a basic configuration by using the following options:
1. Cloud account: A method to connect to a type of resource provider
a. Such as vCenter, Amazon Web Services, Google Clouod Platform, Azure, VMware Cloud Foundation, VMware Cloud on AWS
b. Cloud accounts connect the vRA system to multiple types of resource providers.
You could have multiple cloud accounts for each type of system.
2. Cloud zone: Identify subsystems for provisioning within a cloud account
3. Project: Define which users can use which resources
4. One or more flavors: A group of virtual machine sizes
5. One or more image mappings: Types of images, such as operating systems or applications.
Click Guided Setup in the upper-right corner to see the simple configuration process. You can click each step for detailed instructions.
Add a Cloud Account
Consult and then create new cloud account
# How to setup new cloud account
1. Login to vRA
2. Navigate to Infrastructure -> Connections -> Cloud Accounts
3. Select the type of resource provider
a. Fill in the required account information
b. click Validate # Verify the connection for any issue
Create Cloud Zone and enable Provisioning
After successfuly creating the cloud account, create a cloud zone and enable provisioning.
# How to create cloud zone
1. Navigate to Infrastructure
2. Expand Configure -> Cloud Zones
3. Click "+ New Clound Zone"
a. Summary tab
i. Select the required data center/region
ii. Enter the cloud zone name
ii. Select Placement Policy
- Default # VM randomly place
- Binpack # Select high enough resource to deploy
- Spread # DRS spread
iv. Select the folder
v. In Capabilities section
- Capability tags # Ennter the capability tab
b. Compute tab
i. In Include all unassigned compute drop down selection
- Include all unassigned compute
- Manually select compute
- Dynamically include compute by tags
c. Projects tab
Create a Project
Projects organize your vRealize Automation system into resources that are associated with users and groups. Projects map compute resources to users and groups.
Projects organize and govern which users can use which cloud zones to deploy VMware Cloud Templates in your cloud infrastructure. Anyone who creates and deploys VMware cloud templates must be a member of at least one project.
Each project must have at least one cloud zone for resources. You can connect multiple cloud zones to a project. The cloud zones can be of different types: vCenter Server, Google, AWS, and others.
For each zone, you can set a zone priority and you can limit the amount of resources that the project can use. The possible limits include the number of instances, memory, and CPU. For vSphere cloud zones only, you can configure storage limits. The default value of 0 gives you unlimited instances.
# How to create a project
1. Navigate to Infrastructure -> Administration -> Projects, and click New Project
2. User tab
i. Add users or groups
ii. Deployment sharing
- Deployments are shared between all users in the project. # Select the option
Note:
Users and groups are assigned different roles.
i. Administrator: Can change project configuration, add or remove users, and add or remove cloud zones.
ii. Member: Can use the project services and deploy VMware Cloud Templates.
iii. Viewer: Can only view VMware Cloud Templates and the deployments in this project but cannot deploy VMware Cloud Templates.
3. Provisioning tab
Add provisioning
i. Add previously defined cloud zone
ii. Define resources for this project
- Select the previously defined cloud zone
- Provisioning priority # Default 0 (highest), set to 1
- Instance limit # Default 0 (unlimited)
- Memory limit (MB) # Default 0 (unlimited)
- CPU limit # Default 0 (unlimited)
- Storage limit (GB) # Default 0 (unlimited)
Creating a Flavor Mapping
Flavor mappings are virtual machine sizes. You can create any combination of size configurations.
A flavor mapping is where you define target deployment sizes for a specific cloud account. Set the number of CPUs and the size of the memory. If you click the (+) icon at the end of the line, you can add multiple cloud accounts that work with the same size flavor.
# How to create new flavor mapping
1. navigate to Infrastructure -> Configure -> Flavor Mappings
2. Enter Flavor Name
3. Configuration
a. Select cloud account/Region
b. Set CPU value
c. Set memory size (GB)
Note:
Normally, we define size as Small, Medium, and Large
Creating an Image Mapping
In vCenter, the image mapping is a virtual machine template. In other cloud types, they are referring to different names.
An image mapping is where you define target deployment images for a specific cloud account. You can map images to any kind of template, such as predefined web server, predefined database servers, predefined application system. For a vCenter cloud account, the target deployment image is a virtual machine template.
Note: You can map images from multiple cloud accounts to the same image mapping.
# How to create an image mapping
1. Navigate to Infrastructure -> Configure -> Image Mappings
2. Enter Image Name
3. Configuration
a. Select cloud account/Region
b. Select predefined image (aka template)
c. Constraints # Configure tags (key:value pair) as constraints
Note:
You can add/map images from multiple cloud accounts to the same image mapping.
Testing Project with cloud zones
Testing the project with cloud zone to verify the project and cloud zone have been configured properly.
# How to test project with cloud zone configuration
1. Navigate to Infrastructure -> Administration -> Projects
2. Click Test Configuration
3. Select the project
4. Select test options
a. Single machine
b. Two machines with network
c. Two machines with network and storage
d. Two machines with network, storage and load balancer
5. Select Machine Properties
a. Falvor size
# Small, Medium or Large
b. Image mapping
# Select the image mapping
c. Constraints
# Add constraints
6. Click Simulate
Note:
The simulation does not deploy VMware cloud template or virtual machines.
Cloud Templates
Cloud templates are specifications that define virtual machines, applications, and services on cloud resources.
Note: Cloud templates enable the automation of deployments
Customization is the process of configuring a standard template referenced in an image mapping so that it is better suited to a specific purpose. This process can include running commands after deployment, creating and editing configuration files, creating user accounts, and installing software.
cloud-init is an industry-standard configuration package that enables you to send configuration instructions to virtual machines as they are being deployed to customize them. cloudConfig is the VMware implementation of cloud-init.
Creating a Cloud Template
When you create a cloud template, you must select a project for it to be associated with. A cloud template can be restricted to a single project's users or it can be available to users in all projects.
# How to create a cloud template
1. In vRA, click the Design tab
2. Click Cloud Templates
3. Click +NEW FROM
4. Click Blank Canvas
5. In New Cloud Template window
a. Name # Enter cloud template name
b. Description
c. Project # Select the predefined project
d. Cloud template sharing in
- Share only with this project # Can select it to restrict the project scope
e. Service Broker
- Allow an administrator to share with any project in this organization
# Select this to share the cloud template
Cloud Template Designer
Use the cloud template designer to automate the deployment of machines, networks, and more.
The vRealize Automation cloud template designer can be used to create simple cloud templates the deploys a single machine and connects it to a single network. You can create cloud templates that deploy multiple machines, connect those machines to multiple networks, add disks to the machines, load balance the machines, configure the machines, and so on.
The Configuration pane has three tabs that enable you to configure the components that you dragged to the design canvas.
# When you select a component in the design canvas
a. the Code tab highlights the YAML code that implements the functionality provided by the component, and
b. the Properties tab enables you to configure the settings of the component
c. The Inputs tab enables you to define inputs,
which enables you to prompt the end user to control aspects of how the cloud template deployment is configured.
Resource Pane
The resources pane is on the left. You can select components and drag them to the design canvas.
# Resource types are available for the following cloud systems and technologies
1. Cloud Agnostic
a. Machine
b. Load Balaner
c. Network
d. Security Group
e. Volume
2. vSphere
a. Machine
b. Disk
c. Network
3. NSX
4. Amazon Web Service (AWS)
a. Instance
b. Volume
5. Configuration Management
- Configuration management technologies, such as Ansible, Ansible Tower, Puppet, and Terraform
6. Google Cloud Platform (GCP)
a. Machine
b. Disk
7. Kubernetes
a. K8s Cluster
b. K8s Namespace
c. Supervisor Namespace
8. Microsoft Azure
a. Machine
b. Disk
9. Terraform
Design Canvas Pane
The Design Canvas pane is where you drag components and connect those components to visually design your cloud template. Icons at the top of the design canvas provide useful functions such as delete, duplicate, zoom, undo, redo, and so on. As you drag components to the design canvas, vRealize Automation automatically writes the YAML code, which appears in the Configuration pane.
# You assemble the basic components in the design canvas:
1. Select an item in the Components pane and drag it to the design canvas
2. Connect items like virtual machines, networks, and storage.
Configuration Pane
When you select a component in the design canvas, the YAML code that implements the functionality provided by the component is highlighted on the Code tab. The Properties tab enables you to configure the settings of the component. The Inputs tab enables you to define inputs that enable you to prompt the end user to control aspects of how the cloud template deployment is configured.
The Configuration Pane has three tabs that enable you to configure the components that you dragged to the design canvas.
# Three tabs
a. Code
- YAML code
b. Properties
- Selected item's properties
Note:
Select "Show all properties" # This will show all properties, so you could update required properties
c. Inputs
a. Configure for user input
b. Click "+NEW" to add multiple inputs if required
Testing and deploy the cloud template
Before performing a deployment from a cloud template, you can click TEST to confirm that the YAML code is syntactically valid, the constraints specified with tags can be met, and so on.
To perform a deployment from a cloud template while you are in the cloud template designer, click DEPLOY.
Alternatively, you can click CLOSE to return to the Design > Cloud Templates page. On the Cloud Templates page, you can select a cloud template by selecting its check box and click DEPLOY.
Renaming resources
You could rename resources in the cloud template by editing the properties and editing the YAML code.
vRealize Automation Marketplace
Marketplace provides finished cloud templates and open virtualization images that are managed in VMware Marketplace. The Solution Exchange files that are tagged with Cloud Assembly appear on the vRealize Automation Cloud Assembly Marketplace tab. You must provide the My VMware account credentials to download content from marketplace.
# How to add My VMware account
1. Navigate to Connections -> Integrations or by clicking the Add My VMware account link.
2. The GET button is enabled after adding the My VMware account.
3. Click GET to add the cloud template or image to an existing project or download to your local computer.
Cloud-Agnostic VMware Cloud Templates
The cloud-agnostic counterparts instruct vRealize Automation to create resources. The choice of compute platform can be deferred until the time of deployment rather than hard-coding the decision into the cloud template.
User inputs
Inputs are useful when creating cloud-agnostic cloud templates because they allow you to enable the end user to select the target platform. User can select from the option list.
# Example of input selection using constraints, and constraints are defined as tags (key:value pair)
- title: Amazon
const: 'platform:aws'
- title: Azure
const: 'platform:azure'
- title: GCP
const: 'platform:GCP'
- title: vSphere
const: 'platform:vsphere'
Required configuration
To use cloud-agnostic resources in a cloud template, you must configure the following features for each cloud platform:
1. Cloud accounts
2. Cloud zones
3. Flavor mappings
4. Image mappings
5. Capability tags
Select/create cloud agnostic template
a. Image Name
b. Configuration
i. Account/Region
ii. Image # select the image
iii. Constraints # enter the constraints (key:value pair)
Capability Tags and Constraints Tags
Administrators apply capability tags to resources, such as cloud accounts, cloud zones, network profiles, and so on, so that cloud template designers can target the resources they want to deploy to. Cloud template designers apply constraint tags to resources such as machines, networks, disks, and volumes.
Capability tags can be set on resources such as:
• Cloud accounts
• Cloud zones
- env:production
- env:dev
Note:
These tags instruct vRealize Automation that the deployment of this machine is constrained to cloud zones that have the matching capability tag.
• Kubernetes zones
• Network profiles and networks
• Storage profiles and storage
• Compute
Constraint tags can be set on:
• Cloud Templates
• Image mappings
• Projects
Resource Grouping
You do not need to tag extensively because of a mechanism called grouping in vRealize Automation deployments. By understanding resource grouping, you can reduce the number of resources that must be tagged in vRealize Automation to create cloud-agnostic cloud templates.
To understand grouping, you must first understand the different types of links in cloud templates:
# View grouping in cloud template design canvas, it shows the link(s)
• Explicit links
# Explicit links are indicated by a solid arrow. Explicit links indicate dependencies between machines.
# Symbol ._______>
• Implicit links
# Implicit links are indicated by a dashed arrow.
# Implicit links are typically created when somewhere within an object you are referencing information from another object.
# Symbol .-------->
• Hard links
# Hard links indicate connections between resources. Grouping is performed only based on the hard links.
# Hard links are indicated by a solid line.
Note:
1. Grouping is performed only based on the hard links. Explicit links and implicit links are not considered during the grouping process.
2. vRealize Automation knows to deploy the objects (components) together.
cloudConfig and Cloud-init
CloudConfig
You can use cloudConfig and cloud-init to customize a single cloud template so that it can be deployed and run on any cloud:
- Many commands work on all supported operating systems.
- You can also combine YAML with cloudConfig to customize a single cloud template so that different commands are run on different cloud deployments.
cloudConfig sends instructions to cloud-init:
• cloud-init is an industry-standard software package that allows customization.
• cloudConfig is the cloud template YAML code that sends instructions to cloud-init.
Note:
Cloud-init configuration software installed inside virtual machine.
Cloud-init
cloud-init is a set of Python scripts that initialize cloud instances of Linux machines. The cloud-init scripts configure SSH keys and run commands to customize the machine without user interaction.
Note:
1. All operating systems do not support all cloud-init commands.
2. cloudConfig sends instructions through the CD-ROM drive on the virtual machine template.
3. Output from cloud-init can be found in the /var/log/cloud-init-output.log file after the virtual machine is deployed.
Create vSphere template that support cloud-init
The procedure for creating the CentOS and Ubuntu templates in vSphere is a relative task.
# To create a vSphere template that supports cloud-init:
1. Install cloud-init on the vSphere virtual machine. Each operating system has unique configuration requirements.
a. Use yum to install cloud-init in CentOS.
b. Use apt-get to install cloud-init in Ubuntu.
2. Ensure that you set the CD-ROM on the virtual machine template to passthrough mode.
a. Edit virtual machine in vSphere client
i. Set CD/DVD drive to client Device
ii. Device Mode -> Passthrough CD-ROM
3. End your configuration with the cloud-init clean command.
Note: After you complete the configuration, enter the the command
cloud-init clean
After you enter this command, you must not modify your template virtual machine.
Instead, the virtual machine is shut down and converted into a template.
CloudBase-init
CloudBase-init is the Windows equivalent of Cloud-init
cloudConfig
The cloudConfig YAML format/syntax is very IMPORTANT and case sensitive.
# cloudConfig format
1. The cloudConfig
section must line up under other parts of machine properties (image, flavor, networks, and so on).
2. The cloudConfig directive begins with a lowercase c
and has an uppercase C in the Config.
cloudConfig: | <---- Syntax
# A pipe character "|" must occur after cloudConfig directive.
# All commands after the pipe character are sent to the virtual machine cloud-init software package, after
the image is deployed.
# These commands are run only on FIRST boot
**** Important - YAML format ****
a) # <This is comment line> <---- In YAML, a comment line starts with #
b) After the colon (:), add two spaces, then enter the pipe character (I)
c) The next line after
cloudConfig: |
should be indented two spaces, followed by cloudConfig directives, such as
users, runcmd, hostname, and so on
d) After the directive (users, runcmd, and so on), the next line should begin with
two spaces followed by a hyphen and a space
cloudconfig: | # two space between ":" and "|"
- name: ${input.user}
cloudConfig commands
The following commands are available in cloudConfig
Important: Run commands after VM deployment
# There are ":" after the cloudConfig commands
1. users:
2. hostname:
3. runcmd:
4. packages:
Note:
All cloud-init features are not supported in all operating systems.
To create local users in Linux virtual machine by using the users directive
cloudconfig: | # two space between ":" and "|"
users: # two space before "u" and "c"
- name: ${input.user}
# two space before "-" and "u"
# two space between ":" and "$"
sudo: ['ALL=(ALL) NOPASSWD:ALL']
# two space between ":" and "["
# It creates the following file
/etc/sudoers.d/dont-prompt-<your-username>-for-sudo-password
groups: sudo # add user to sudo group
# or use "groups:" command to create groups
shell: '/bin/bash' # set user bash shell
Note:
a. You cannot set the password of a user in the users: directive of cloudConfig. However,
b. you can set the password with runcmd: after the user is created.
Set, configure or customize the virtual machine host DNS name
1. cloudconfig hostname directive, or
cloudConfig: |
hostname: ${input.hostname}
Note: This directive is NOT supported in all operating systems
2. hostnamectl # Linux command
cloudConfig: |
runcmd:
- hostnamectl set-hostname ${input.hostname}
Note: Linux command "hostname" is set using hostnamectl command, works for all Linux operating systems
Running Commands after deployment - runcmd
You can use the runcmd: directive to run commands in the virtual machine after deployment.
# To use runcmd in YAML:
• Begin with
runcmd:
• Begin the next line with a hyphen (-), followed by a space, and followed by the command.
• Almost any command that can be run interactively can be run in runcmd.
• You can edit files with the sed editor.
• Commands must be self-contained. You cannot provide user input to a runcmd command.
runcmd:
- mkdir -p /tmp/test
- hostnamectl set-hostname ${input.hostname}
Installing software after deployment
Use the packages: directive to install software
# Prerequisite
Your virtual machine must have access to either a local repository or to the Internet to obtain the software
Note:
packages:
directive works on different versions of Linux.
a. Ubuntu uses apt-get to install software, and
b. CentOS uses yum to install software, and
c. cloud-init can use the packages: directive on both operating systems.
# How to update repositories in the deployed virtual machine
You can include a directive before packages:
which updates your repositories in the virtual machine.
cloudConfig: |
runcmd:
-hostnamectl set-hostname ${input.hostname}
package_update: true
package_upgrade: true
packages:
- apache2 # Install apache2 software
cloudConfig in image mappings
You can add cloudConfig commands or scripts to an image mapping:
- Enter only cloudConfig commands
- Image commands are not interactive
- Image mapping commands take precedence over cloud template commands
Note:
a. Inputs are not allowed.
b. If you have cloudConfig commands in both an image mapping and a cloud template,
the commands are combined into a single list of commands.
c. If a conflict occurs between the cloudConfig commands in an image mapping and the cloudConfig commands in a cloud template,
the directives in the image mapping take precedence.
# How to add cloudConfig commands to an image mapping
1. Edit the required image mapping
2. Navigate to Configuration section, click Edit in "Cloud Configuration"
3. Type the commands in the expanded editing area
runcmd:
- hostnamectl set-hostname '<hard-code-name-here>' # command can NOT take user input
packages:
- apache2
Enter only the commands that might follow cloudConfig: in a YAML cloud template,
using the same spacing and formatting that you might if the commands are in a cloud template.
cloudConfig recommendations in vSphere
Follow these recommendations when combining cloudConfig and vSphere
1. The virtual machine that is deployed should have a DHCP IP address.
2. Do not combine a vSphere customization specification with a cloud template that uses cloudConfig.
cloudConfig is not designed to be compatible with the vSphere customization specification and results are unpredictable.
The most common result is that the networking is not properly configured.
cloudConfig uses the network during its configuration operations. The virtual machine template must have a live connection to the network before configuration commands are run. In general, this restriction forces networking to be DHCP-only. You can use a static IP address, but doing so requires a workaround.
cloudConfig Logs and Scripts in a Deployed Machine
The following files in a deployed machine has key troubleshooting information
1. Output log file
/var/log/cloud-init-output.log
2. Main log file
/var/log/cloud-init.log
3. Main cloudConfig scripts directory
/var/lib/cloud/instance/scripts
4. Main cloudConfig script
/var/lib/cloud/instance/user-data.txt
5. Runcmd script file
/var/lib/cloud/instance/scripts/runcmd
You can also examine the actual commands sent to cloudConfig by vRealize Automation
1. Open the deployment in vRealize Automation
2. Click History
3. Click Provisioning Diagram
4. Use the slider to turn the Dev mode on
5. Click the Cloud icon to the left of Dev mode
6. Click Save to save the JSON file
You must use a JSON viewer (such as Notepad++ with a JSON plug-in installed) to read the file
7. Search for cloudConfig
YAML
YAML is a flexible, easy language that you can use to quickly configure and manage infrastructure as code.
Infrastructure as code is the process of provisioning infrastructure (machines, networks, load balancers, storage, and so on) through code rather than manually configuring physical hardware or using configuration tools manually.
In vRealize Automation, we use the YAML language to manage infrastructure as code.
Indentation in YAML
Unlike many computer programming languages, YAML is sensitive to indentation:
1. In YAML, indentation denotes nested blocks
2. All items in a nested block must be indented equally
3. Use spaces to indent
a. Tabs are not allowed.
b. You can use any number of spaces to indent a section.
Subsections that are at the same level must have the same number of spaces
4. The YAML editor in vRealize Automation draws vertical lines to show you where you have used spaces to indent code.
Comments in YAML
As the cloud templates become more complicated, include comments for documentation:
1. A # symbol anywhere in the YAML code causes everything following the # to be treated as a comment.
2. A # symbol at the beginning of a line makes the entire line a comment.
3. A # symbol at the end of a line adds a comment about that specific line.
4. A # symbol that is enclosed by single or double quotation marks is not treated as a comment.
Key-Value Pairs in YAML
YAML stores data in a map that contains keys and values
1. The format is
KEY: VALUE # There is a space between ":" and "valule"
2. The value can be enclosed in single quotes
Note: If you have several types of key-value pairs that can be used,
the order in which you enter them into the YAML code does not matter.
cloud_vsphere_network_1:
type: Cloud.vSphere.Network # key is "type", and value is "Cloud.vSphere.Network"
properties:
networkType: existing # there are three key:value pairs under properties
name: VMw-Production
networkCidr: 172.20.10.0/24
Lists in YAML
Lists are used to store a collection of values in order. Lists are useful when you define variables or inputs.
1. Lists begin with a key followed by a colon (:)
2. Each list item starts with a hyphen (-)
3. All list items in a list must be indented equally
enum:
- VMW-Small # small size vm
- VMW-Medium # medium size vm
- VMW-Large # large size vm
Variables in YAML
Variables in YAML start with the $ character
1. Variables can be used to reference other components in the YAML code
2. Variables can also be used with user inputs
- Variables can also be used with user inputs. When referenced, these variable names start with .input.
- The first part of the variable name (for example, resource.) describes the part of the YAML code that the variable comes from.
- If you connect two objects in the design canvas, a variable that points to the connected object is added automatically in the YAML code to the object that connected to it. These variables always end with the .id text
resources: # resouces section describes all the resouces used
Cloud_vSphere_Machine_1: # This is the first virtual machine
type: Cloud.vSphere.Machine
properties: # describe the vm properties
image: VMW-Centos # image used
flavor: '${input.SelectFlavor}' # single quote the value, and using variable ${input.SelectFlavor} from the user input selection
customizationSpec: Lin-Cust
networks:
- network: '${resource.Cloud_vSphere_Network_1.id}'
Cloud_vSphere_Network_1:
type: Cloud.vSphere.Network
User Inputs in YAML
User inputs enable the user to select options from a list of choices
1. The list is defined in YAML
2. Assign the variable any name you like
3. Define the list as a type of string and delineate the list items under enum
enum:
- VMW-Small
- VMW-Medium
- VMW-Large
4. Use the variable anywhere in the YAML code
a. Begin the variable with '${input.
b. End with the variable name and a right brace
Example: '${input.SelectFlavor}'
Note:
a. When you define an input variable, it is listed in the inputs section (plural)
b. When you reference the variable, it is singular ${input.<variable name>}.
inputs: # define the input variable, listed as "inputs" plural
SelectFlavor:
type: string
enum:
- VMW-Small
- VMW-Medium
- VMW-Large
resources: # define the resource (as pural)
Cloud_vSphere_Machine_1:
type: Cloud.vSphere.Machine
properties:
image: VMW-Centos
flavor: '${input.SelecFlavor}' # Rreference input variable (singular 'input')
Formatting Text in a Cloud Template
To create a user-friendly input on your choice list, you might want to concatenate the text or change the case.
# Example
inputs:
SelectCloud:
type: string
enum:
- AWS # capability tags - cloud:aws
- GCP # capability tags - cloud:gcp
- Azure # capability tags - cloud:azure
- vSphere # capability tags - cloud:vsphere
resources:
Cloud_Machine_1:
type: Cloud.Machine
properties:
constraints:
# Use concatenated text to form the exact name of a capability tag that we defined in vRA
- tag: ${'cloud:""' + to_lower(input.SelectCloud)}
# Note:
# a. The colon (:) is a special character in YAML,
# To use a colon in a string, two double quotes must follow the colon :""
Note:
As an alternative to use "enum" for user selection, could use "oneOf" instead, but few more lines of code
oneOf:
- title: AWS
const: 'cloud:aws'
- title: Azure
const: 'cloud:azure'
- title: GCP
const: 'cloud:gcp'
- title: vSphere
const: 'cloud:vsphere'
When defining a drop-down menu using oneOf, each entry in the list is a pair.
Each pair consists of a value that the user is shown in the drop-down menu and a value that is returned to vRealize Automation.
Using Escape Characters
Configuration files often require the following special characters
1. The standard escape character in YAML is the backslash (\), such as
\$
2. You can escape a single quote (') by enclosing it in a pair of double quotes,
"'"
3. You can escape a colon (:) by following it with two double quotes,
:""
Evaluating Expressions in a Cloud Template
You can set values based on the evaluation of an expression.
# Example
'${input.SelectCloud == "vSphere" ? "Production_VMs" : ""}'
1. The == expression tests the value of the variable input.SelectCloud, if it equals what follows,
in this case "vSphere"
2. The questoin mark (?) expression is the equivalent to a Then clause in an If/Then/Else expression
a. If equals to "vSphere", then set the value to "Production_VMs", else
b. set the value to blank ""
3. The single quote (:) separate two values
Note: Other conditional expressions
a. Equality operator
== != # equal, not equal
b. Logical operator
&& # logical operator (and)
|| # logical operator (or)
! # logical operator (not)
c. Relational operators: > < >= <=
d. Conditional express always use the pattern
conditional-express ? true-answer : false-answer
Tags and Storage Configuration
Tags allow resources to be managed and categorized. Storage is one of the resources. Dividing storage into storage tiers and managing storage with storage profiles and tags maximizes the return on storage investment.
Tags in vRealize Automation
Tags are available in vRealize Automation:
1. Tags are labels that you apply to resources
2. Tags can be of the form key or key:value
3. Different types of tags are available
a. Capability tags
b. Constraint tags
c. Resource tags
Note:
a. vRealize Automation tags are different from vSphere tags.
b. Tag virtual machines that are deployed by vRealize Automation with a tag, the tag is visible in vSphere.
We use tags as contraint tags in vRA. Tags are like labels.
# How to use tags in vRA, example
1. We create tag in cloud zone, cz:aws
2. Then assign it to resource, cloud zone
3. We use it as constraint in configuration
resources:
Cloud_AWS_EC2_Instance_1:
..
constraints:
- tag: 'cz:aws' # use the tag in constraints
Capability Tags
Capability tags enable you to categorize resources based on the capabilities that they provide. You can apply capability tags to the following types of resources
• Cloud accounts
• Integrations
• Cloud zones
• Virtual private zones
• Kubernetes zones
• Network profiles
• Storage profiles
Note:
1. tags are <key:value> pairs
2. Enter the tag in section for the resources:
Capabaility tags
net:production # Examples
cz:aws
Important Tag usage:
We can define capability tags in cloud template and in project.
When we define capability tags once in the project,
it will inherit to all cloud template belongs to this project.
Constraint Tags
Constraint tags enable you to govern how vRealize Automation selects resources to use during deployments. You can apply constraint tags to the following types of resources
1. Cloud templates
2. Image mappings
3. Projects
Example in cloud template code pane
constraints:
- tag: 'net:production'
# contraints in projects
a. Network constraints
b. Storage constraints
c. Extensibility constraints
We can define tags in project constraints.
Important:
If tag defines in cloud template, and also define in project,
the project tags take precedence.
Resource Tags
We can define the resource tag, for example in Project, when click Provisioning tab, under Resource Tag section.
Such as define resource tag departement:engineering
Note: When VM are deployed from this project, will inherit this tag.
When we create a cloud template, we must select a project. This means the cloud template created, will also inherit this resource tag at project leve. In production, we have lots of deployments. When in Deployment tab/window, we can use this tag or tag to filter the deployment.
Tags in Projects
You can specify network constraints, storage constraints, and extensibility constraints on a project. Project constraint tags take precedence over cloud template constraint tags. Additionally, you can set resource tags on a project.
# How to set tags in projects
1. Edit the project
2. Select Provisioning tab
a. Zones
Add the required zone, and zone may have capability tag
b. Resource Tags
Tags # Enter the required tag to define the resource
c. Constraints # define or configure constraints for the project
i. Network constraints
ii. Storage constraints
iii. Extensibility constraints
Note:
If the same constraint is specified in both the project and the cloud template,
then the constraint specified in the project takes precedence.
Resource tags result in machines deployed from a cloud template being tagged in the compute platform.
# Example
If the machine being deployed by vRealize Automation is a vSphere VM,
then the VM will be tagged using the tagging mechanism built in to vSphere.
Hard, Soft, and Not Modifiers
Multiple tag modifiers are available
# Available tag modifiers
a. key:value
b. key:value:hard
# The hard modifier indicates that the constraint tag is a requirement
If the constraint cannot be satisfied, then deployment fails.
c. key:value:soft
# The soft modifier indicates that the constraint tag is a preference.
# If vRealize Automation can find a resource that satisfies the constraint tag,
then vRealize Automation uses that resource.
If vRealize Automation cannot find a resource that satisfies the constraint tag, then
the deployment can proceed using another resource even though it does not satisfy the constraint tag.
d. !key:value # Rarely in used
The hard modifier indicates that the constraint tag is a requirement. If the constraint cannot be satisfied, then deployment fails. key:value is synonymous with key:value:hard. The soft modifier indicates that the constraint tag is a preference. If vRealize Automation can find a resource that satisfies the constraint tag, then vRealize Automation uses that resource. If vRealize Automation cannot find a resource that satisfies the constraint tag, then the deployment can proceed using another resource even though it does not satisfy the constraint tag.
Tagging Strategies
When developing your tagging strategy, follow these suggestions
1. Tag enough to be useful. Do not tag excessively
2. Resource grouping can reduce the amount of tagging required
3. Use key:value style tags rather than key style tags
4. Perform a business requirements analysis and base your tagging strategy on those requirements
# Access the tags in Tag Management
1. Tags tab - List all the tags
a. Key
b. Value
c. Origin
Click + NEW TAG to create new tag
2. Tag Usage
Search the tag usage
Storage Management
Storage management is a key part of resource management. Unlike CPUs and memory, storage is not homogenous. Storage is available in multiple types, with each type having different capabilities. vRealize Automation uses storage profiles to help you manage different types of storage.
Different types of storage are available with different capabilities
- Some storage is more expensive than others
- Some storage systems are fast (such as SSD)
- Some storage arrays have a small amount of free space
- Some storage arrays have different IOPS characteristics
- Some storage systems (such as NFS) have different characteristics than others
vSphere VM Storage Policies
vSphere VM storage policies can be used to define your storage
- Storage policies can be based on host-based rules, vSAN rules, or tags
- After a VM storage policy is defined, it must be assigned to compatible storage.
- An easy method is to create tags in vSphere and assign them to datastores. Then create tag-based VM storage policies.
1. In vSphere client, navigate to Home -> Policies and Profiles
2. Select VM Storage Policies
Create, check or delete VM storage policies, such as
- Gold-vSphere-Storage-Policy
- Silver-vSphere-Storage-Policy
- Bronze-vSphere-Storage-Policy
vRealize Automation storage profiles can directly interface with vSphere VM storage policies. vRealize Automation storage profiles can also be used on other cloud accounts.
Note:
In vRA, if you do not constrain a disk or set a storage policy in a blueprint (cloud template), then
the default storage policy is used.
vSphere Tags
vSphere VM storage policies can use vSphere tags. Like tagging in vRealize Automation, vSphere tags enable you to label objects in your vSphere inventory, such as datastores.
While vRealize Automation tags and vSphere tags are similar in many ways, you must recognize that these tags are separate mechanisms that operate independently of each other.
The vRealize Automation tags and vSphere tags differ in their terminology. With vRealize Automation tags, you set a key and a value. With vSphere tags, you set a category and a tag. A vSphere tag category is analogous to a vRealize Automation tag key. And, a vSphere tag is analogous to a vRealize Automation tag value.
# How to create vSphere Tags and Customs Attributes
1. In vSphere client, navigate to Home -> Tags & Custom Attributes
2. Click Tags tab
a. New # create new tag, and assign tag to vSphere datastores
i. Category # similar to vRA tag "key"
ii. Tag Name # similar to vRA tag "value"
b. Edit
c. Delete
d. Add Permission
Creating vRealize Automation Storage Profiles
To create a storage profile in vRealize Automation that is related to a vSphere VM storage policy:
# How to create vRealize Automation Storage Policy
1. Navigate to Infrastructure > Configure > Storage Profiles
2. Click +NEW STORAGE PROFILE
3. Enter a name and description for the cloud template/blueprint
4. Select your cloud account / region
5. Enter the storage profile name
6. Configure the storage profile.
a. Disk type (select one of the following disk type)
i. Standard disk
ii. First class disk
# Use for data disk or persistent data disk, independant of OS disk/boot disk
b. Select the vSphere VM storage policy in the Storage policy drop-down menu
Note:
- vRA auto discover vSphere VM storage policies
- vRA data collection runs every 10 minutes
c. Datastore/cluster # select the datastore or cluster
Note:
If you select the storage policy, it will define the datastore/cluster
d. Provisioning type
i. Thin # use default thin provisioning to save disk space
ii. Thick
e. Shares # keep default
f. Limit IOPS # keep default
g. Disk mode
i. Dependent
ii. Independent
- Supports encryption
- Preferred storage for this region # Set the vRA storage profile as preferred in the region
h. Create or attach a capability tag
i. enter vSphere defined tags, such as
storage:gold-vsphere-tag
Note:
1. We could use tags from other cloud providers, such as aws, azure
2. define the capability tags, and use in constraints
7. Click CREATE.
# How to view the latest collection status in vRA
1. In vRA, select Infrastructure -> Connections -> Cloud Accounts
2. Open the cloud account
3. Verify the Status section
Note:
vRA data collection service run every 10 minutes to discover the cloud account resources, such as
network, storage, VM, tags, and so on.
How to add and define the 2nd disk to the virtual machine
# Process to add and define the 2nd disk to the VM
1. Create new vRA storage profile
Select vSphere storage policy
2. Assign the vRA storage policy to the new disk
Note:
In cloud template design canvas, when you drag and drop a disk to the canvas, if you
do NOT specify vRA storage policy, it will place the 2nd disk in the same vSphere datastore, and
use the same vRA storage profile (vSphere storage policy) as the OS disk/boot disk/base disk.
Preferred vRealize Automation Storage Profiles
In a Cloud Account (region), one storage profile can be marked as the preferred storage for that region.
# To mark a storage profile as the preferred storage:
1. Navigate to Infrastructure > Configure > Storage Profiles.
2. Click BROWSE on the catalog card for your cloud account / region.
3. Click the storage profile that you want to set as default for that cloud account.
4. Scroll down and select the Preferred storage for this region check box.
5. Click SAVE
The preferred storage profile is overridden by a storage constraint tag on a machine in a cloud template. Another way of overriding the preferred storage profile is by specifying storagePolicy on a disk in a cloud template.
Storage Constraint Tag on Machines
You can specify the storage location for the base disk of a machine by using a storage constraint tag.
# Example cloud template virtual machine properties YAML code
resources:
Cloud_vSphere_Machine_1:
type: Cloud.vSphere.Machine
properties:
..
storage:
constraints:
- tag: 'storage:gold-vsphere-tag' <---- this tag has been defined in vRA storage profile "Capability tags"
If you specify a storage location by setting a storage constraint tag on a machine, then the base disk and all the other disks are placed on that storage. However, you can override the storage location of the secondary disks by setting storagePolicy.
Storage Policy on a Disk
You can specify the storage location per disk by setting storagePolicy on a disk resource.
# Example configure storagePolicy on virtual machine disk
Cloud_vSphere_Disk_1:
type: Cloud.vSphere.Disk
properties:
capacityGB: 10
storagePolicy: Silver-vSphere-Storage-Policy <------ Storage Policy is defined in vRA "Storage policy" section
Storage policy - Order of precedence
A storagePolicy on a disk overrides a storage constraint tag on a machine. A storage constraint tag on a machine overrides the preferred vRealize Automation storage profile. A storagePolicy on a disk overrides the preferred vRealize Automation storage profile.
resources:
Cloud_vSphere_Machine_1:
..
storage:
constraints:
- tag: 'storage:gold-vshpere-tag'
----Override----> vRA storage profile - "Preferred storage for this region"
-> Preferred storage policy for this region is
"Silver-vSphere-Storage-Policy"
..
cloud_vsphere_Disk_1:
type: cloud.vsphere.Disk
properties:
capacityGB: 10
storagePolicy: Bronze-vSphere-Storage-Policy
-----override---> Cloud_vSphere_Machine_1 storage constraints "storage:gold-vsphere-tag"
vRealize Automation Volumes
You can see volumes by navigating to Infrastructure > Resources > Volumes
A volume is a logical drive that was either discovered through data collection on cloud accounts or is associated with workloads that were provisioned by Cloud Assembly. A volume is another item in vRealize Automation storage management.
First Class Disks (FCD)
Standard disks are dependent. Standard disks exist with a machine. If you delete the machine, the standard disk is deleted.
First Class Disks have been known by numerous names
- First Class Disks (FCD)
- Improved Virtual Disks (IVD)
- Enhanced Virtual Disks
- Managed Virtual Disks
FCDs are independent of VMs. If you delete a VM with an FCD attached to it, the VM and all its standard disks are deleted but FCDs are not deleted.
If you take a snapshot of a VM, the snapshot captures the state of all (nonindependent) standard disks. On the other hand, you can take snapshots of individual FCDs independent of any VM that the FCD is attached to.
Note:
First Class Disks (FCD) are independent of a specific machine.
FCDs can be used for various use cases:
- Provide persistent storage to containers
- Enable testing using data generated on a production VM without working with, and potentially compromising, the production data.
You create a production VM, attach a FCD to the VM, and put production data into the FCD. When you want to perform testing, you can take a snapshot of the FCD, create another FCD from that snapshot, attach the duplicate FCD to a Test/Dev VM, and safely perform your testing using the Test/Dev VM.
The vRealize Automation REST API provides numerous operations that can be performed on First Class Disks.
NSX-T Data Center
Integrating NSX-T Data Center with vRealize Automation enables access to improved networking capabilities. Using NSX-T Data Center, you can design systems with advanced networking and security features that deliver high-quality services and applications.
NSX-T Data Center is the next-generation product that provides a scalable network virtualization and micro-segmentation platform for multihypervisor environments, container deployments, and native workloads running in public cloud environments.
NSX-T Data Center focuses on providing networking, security, automation, and operational simplicity for emerging application frameworks and architectures that have heterogeneous endpoint environments and technology stacks.
NSX-T Data Center supports cloud-native applications, bare-metal workloads, multihypervisor environments, public clouds, and multiple clouds.
Like the operational model of VMs, networks can be provisioned and managed independent of underlying hardware. NSX-T Data Center reproduces the entire network model in software. NSX-T Data Center enables network topologies, from simple to complex multitier networks, to be created and provisioned.
NSX-T Data Center provides a complete set of logical networking and security capabilities and services, including logical switching, routing, firewalling, load balancing, VPN, quality of service (QoS), and monitoring. These services are provisioned in virtual networks through cloud management platforms that use NSX-T Data Center APIs.
The three main elements of NSX-T Data Center architecture are the management, control, and data planes.
Network and Security Services
Some components in NSX-T Data Center are distributed, and some components are centralized.
The distributed services in NSX-T Data Center run on hypervisors and are used for east-west traffic, for example, network traffic between two ESXi hosts.
Examples:
switching
distributed routing
distributed firewall
The centralized services cannot be distributed and require an NSX Edge node. The centralized services are used for north-south traffic.
Examples:
centralized routing
firewall
bridging to physical network
load balancing
NSX-T Data Center Edge Nodes
The edge node is a service appliance that runs network services that cannot be distributed to hypervisors.
The edge node is an empty vessel when first deployed. A service router component is initiated when a service is configured. Features of NSX-T Data Center edge nodes:
• Connectivity to the physical infrastructure (T0 uplink)
• NAT
• DHCP server
• Edge firewall
• Load balancer
NSX Edge is a component with the functional goal to provide computational power to deliver the IP routing and the IP services functions. The NSX-T Data Center edge cluster provides high availability in active-active and active-passive modes.
NSX-T Data Center Tiered Routing
Tier-0 router (aka T0 Gateway)
- Created and configured by NSX administrator
- Offers north-south gateway service to physical network
- Supports dynamic routing (eBGP)
- Requires an edge node
Note:
The Tier-0 logical router is a top-tier router.
The Tier-0 logical router runs the Border Gateway Protocol (BGP) and peers with physical routers
Tier-1 router (aka T1 Gateway)
- Created on demand by vRealize Automation
- Offers east-west gateway service
- Is connected to the T0 router
- Requires edge node, only if services are used (NAT)
Tier-1 routers are provisioned on demand when a user from vRealize Automation requests a catalog item that includes outbound or routed network profiles. When vRealize Automation is used with NSX-T Data Center, the Tier-0 router must be deployed as a prerequisite for north-south traffic.
The Tier-1 logical router cannot connect to physical routers directly. It has to connect to a Tier-0 logical router to provide north-south connectivity to the subnets attached to it:
- The NSX Controller instances are responsible for advertising routes between T1 and T0 routers.
- No routing protocol or control VM is required.
- BGP is supported between the T0 router and the physical router, and BGP also supports static routes.
NSX-T Data Center: Cloud Account
To integrate NSX-T Data Center with vRealize Automation, create a cloud account:
1. Log in to the vRealize Automation console as Cloud Assembly Administrator.
2. Navigate to Infrastructure > Connections > Cloud Accounts
3. Click ADD CLOUD ACCOUNT > NSX-T
4. Select NSX Mode
a. NSX-T credentials
i. NSX-T address/FQDN
ii. Username
iii. Password
iv. Select NSX mode
- Manager, or
- Policy
(default): Supported with NSX-T Data Center v3.0 and later.
This option is recommended for greenfield environment, and
it enables vRealize Automation to use the additional capabilities available in the NSX-T Data Center Policy API.
5. Associate the vCenter Server instances
6. Enter capability tags
Network Profiles
Network profiles control placement decisions to choose a network during virtual machine provisioning. They also control the level of isolation for a deployed workload
- Network profiles use the default IP Address Management (IPAM) in vRealize Automation
- Network profiles are used in cloud templates
- The following types of network profiles can be created
a. Routed
b. Public
c. Private
d. Outbound
e. Existing
Network profiles are used to configure network interfaces when VMs are provisioned, and to specify the configuration of NSX Edge devices that must be created when multiple machines are provisioned.
1. Network profiles are created from the Infrastructure tab.
2. Network profiles are consumed by using networkType property in the cloud template.
Cloud_NSX_Network_1:
type: Cloud.NSX.Network
properties:
networkType: # Select one of the avaiable network type
routed
public
private
outbound
existing
Network profiles also support third-party IP Address Management (IPAM) providers, such as Infoblox. When you configure a network profile for IPAM, your provisioned machines can obtain the IP address data, and related information such as DNS and gateway, from the configured IPAM solution.
Discovered Networks
Networks are discovered from vSphere and associated NSX-T Data Center cloud accounts. Click the network to define its attributes.
# How to access vRealize Networks
1. From vRealize Automation, access Cloud Assembly
2. Select Infrastructure -> Resources -> Networks
# There are following tabs
a. Networks # list all discovered networks
b. IP Ranges
c. IP Addresses
d. Load Balancers
e. Network Domains
You can define CIDR, default gateway, and DNS servers for the networks. Networks can be set as default for zone and enable support for public IP (external network)
Public Network
Configure one of the vSphere or NSX-T Data Center port groups as public
- Allow direct external access
- Select the Support public IP check box
- This configuration is used to match networkType: public in the cloud template
- VM is connected directly to the public network
- Public network is also used when other network profiles need external access.
# Create public network
1. Select account/region
2. Name # enter network name
3. Domain # select Active Directory domain if require
4. IPv4 CIDR 172.10.10.0/24
5. IPv4 default gateway
6. IPv6 default gateway
7. DNS servers
8. DNS search domain
9. Select/Enable "Support public IP"
10. Default for zone # optional
Note:
Select the check box to flag the network as a default network for the cloud zone.
During cloud template deployment, default networks are preferred over other networks.
11. Origin # Display where the network is learned
12. Tags # Enter tags if required
Network Profile: Existing
Use existing discovered networks to deploy cloud templates.
# To create a network profile (existing)
1. Navigate to Infrastructure > Configure > Network Profiles
2. Click New Network Profile
3. Click the Networks tab to add an existing network
4. Select None as the isolation policy.
You can add a vSphere port group or an NSX logical switch that vRealize Automation discovered already.
The networks defined on the Networks tab are used to match networkType: existing in the cloud template. The networks marked to support the public IP can also be listed on the Networks tab to match networkType: public in the cloud template. Creating a network profile for existing or public network profile types is not mandatory. The cloud template can choose from the discovered networks. If no tags are specified to select an existing or public network, the default network created for the cloud zone is used.
Network Profile: Private
Isolate provisioned VMs from external access, A private network profile can be created in one of the following ways:
1. Navigate to Infrastructure > Configure > Network Profiles
2. Click New Network Profile
3. On Isolation policy, select one of the followings
a. Select the On-demand network policy
— Do not specify any existing network
— Do not specify an external network and Tier-0 router.
b. Select the On-demand security group policy
— Define an existing network that is discovered or deployed by NSX-T Data Center in the Networks tab.
— vSphere networks are not supported
4. In IP Address Management section
a. Source
i. Internal # select internal
ii. External
b. CIDR # enter the private network CIDR, such as 192.168.20.0/24
c. Subnet Size # select the subnet size, such as /28 (14 IP adddresses)
d. IP range assignment
i. Static and DHCP # select this option
Network Profile: Outbound
Outbound network profiles are on-demand networks that are created during provisioning. An outbound network profile defines internal and external networks that use a translation table for mutual communication.
Single public IP addresses shared across internal networks that need the external connectivity.
Deploying one VM with an outbound network profile
a. Creates one logical switch
b. Creates one DHCP server
c. Creates one Tier-1 router
d. Connects a Tier-1 router to a Tier-0 router
e. Creates a one-to-many SNAT rule
Note:
NSX routes are not advertised.
You must select an external network. The deployed on-demand outbound network is allocated a static IP from the external network for the outbound access (SNAT) rule.
# How to create the outbound network profile
1. Navigate to Infrastructure > Configure > Network Profiles
2. Click New Network Profile
3. On Isolation policy
a. Select the On-demand network policy
4. In Network Resources section # Provide on-demand network resources
a. Transport zone # example, SA-TZ-Overlay
b. External network # example, SA-Production
c. Tier-0 logical router # example, SA-T0-Router
d. Edge cluster # example, SA-Edge-Cluster
5. In IP Address management section # Configure internal IPAM or select external IPAM blocks
a. source
i. Internal # select internal, to use internal IPAM
ii. External
b. CIDR # example, 192.168.20.0/24
c. Subnet size # select from the drop down option, such as /28 (-14 IP addresses)
d. IP range assignement
i. Static and DHCP # select this option
The CIDR value specifies the network address range to be used during provisioning to create subnets.
The subnet size is the size of the on-demand network that is created for each isolated network in a deployment that uses this profile.
One-to-Many: One external IP address is shared among all machines on the network
a. An internal machine can have either DHCP or static IP addresses
b. Every machine can access the external network, but no machine is accessible from the external network
c. The SNAT rule is configured to enable VMs to communicate externally
Network Profile: Routed
Routed network profiles are on-demand networks created during provisioning.
Routed network profiles must use a routed gateway to access external networks.
Note:
1. Network profile configuration for routed profiles is the same as an outbound profile, but
2. you do not define the external network.
End-to-end routable access with unique IP addresses.
# Deploying one VM with routed network profile
1. Creates one logical switch
2. Creates one DHCP server
3. Creates one Tier-1 router
4. Connects a Tier-1 router to a Tier-0 router
5. Advertises NSX routes # It advertise NSX routes
Changing networkType to routed in the cloud template network properties deploys routed networks. NAT rules are not created. The VM can communicate to the external network. The VM can also be reached from the external network. End-to-end routable communication is enabled.
# How to create routed network profile
1. Navigate to Infrastructure > Configure > Network Profiles
2. Click New Network Profile
3. On Isolation policy
a. Select the On-demand network policy
4. In Network Resources section # Provide on-demand network resources
a. Transport zone # example, SA-TZ-Overlay
b. External network
#**** Do NOT select external netwrok
c. Tier-0 logical router # example, SA-T0-router
d. Edge cluster # example, SA-Edge-Cluster
5. In IP Address Management section # Configure internal IPAM or select external IPAM IP blocks
a. Source
i. Internal # select internal
ii. External
b. CIDR # example, 192.168.30.0/24
c. Subnet size # example, select /28 (-14 addresses)
d. IP range assignment
i. Static and DHCP # select this option
Security Groups
Existing security groups can be associated with a VM in the following ways
1. Network profile
a. Assign a common security group to set a minimum-security baseline
b. Security groups added to the network profile are applied to all the VMs in a deployment that use the network profile.
2. Cloud template design canvas
a. More granular or specific security groups (Web, App, or DB)
b. Each VM can be assigned an individual security group.
Note:
Security groups are used to add firewall rules to all machines provisioned with the netowrk profile.
Security groups are visible within Infrastructure > Resources > Security. This view enables you to see all the discovered security groups. You can add multiple security groups to one network profile. Click + ADD SECURITY GROUP to add security groups. The Security Group component in the cloud template can be used to associate security groups directly to the VM network.
Load Balancers
Load balancers in vRealize Automation are available in the following ways
- Add an existing load balancer to a network profile
- Deploy an on-demand load balancer from a cloud template.
# How to add or view load balancer
1. Navigate to Infrastructure > Resources > Networks > Load Balancers tab
2. Click Add Load Balancer
You can either add a cloud-agnostic load balancer or NSX load balancer to the design canvas. The main difference is that an NSX load balancer supports UDP in addition to TCP.
Cloud Template with Network and Security Constructs
You can select from the list of available network and security components to design a simple or complex blueprint, when working on design canvas.
The key difference between networking components available in cloud-agnostic network and NSX is the supported features, such as
- Cloud-agnostic network does not support routed network profiles
- Cloud-agnostic load balancer does not support UDP
Day-2 Actions: Networks
A cloud template can be designed to support Day-2 actions for managing networks after the deployment.
Network Day-2 actions are only supported with Cloud.vSphere.Machine resources. This method does not work for cloud-agnostic machines that are deployed to vSphere. Update deployment constraints on the vSphere machine NIC to move it from one existing network to another existing network in the same network profile. A machine can be moved between static networks or between dynamic networks.
# How to update network
1. Select the network deployment
2. On the top right, click ACTIONS, and select
a. Change Lease
b. Delete
c. Edit Tags
d. Power Off
e. Update <---- Select update to change the network
Day-2 Actions: Security Groups
Security groups can be associated and dissociated with VMs in a deployment.
# How to change/update security group
1. Navigate to deployment -> Topology
a. Topology # select Topology tab
b. History
2. Select the virtual machine
3. Click ACTIONS
a. Add Disk
b. Change Security Group <------- Select change security group
c. Connect to Remote Console
d. Create Snapshot
e. Delete
f. Power Off
g. Reboot
h. Reset
i. Resize
4. On the Change Security Group window
a. click Edit icon
b. + # plus icon to add security group
c. - # minus icon to remove security group
Note:
1. The Day-2 action is supported for a security group that is associated to a single machine only and not for a multimachine cluster.
2. You can perform the following actions
a. Add a security group to the VM
b. Remove a security group associated with a VM (security group will be disassociated but not deleted).
c. Delete a security group (only applicable to on-demand security groups).
Integration with Public Clouds
vRealize Automation supports native integration with public cloud platforms, including
- Amazon Web Services
- Microsoft Azure
- Google Cloud Platform
- VMware Cloud Foundation, and
- VMware Cloud on AWS
Creating cloud accounts in vRealize Automation allows you to integrate with public cloud platforms and deploy services.
# How to add public cloud account
1. Navigate to cloud assembly
2. Expand Connections -> Cloud Accounts
3. Select the cloud acount type to add
Note:
vRealize Automation also supports the cloud account type
a. vCenter Server
b. NSX Data Center for vSphere, and
c. NSX-T Data Center
Amazon Web Services
Amazon Web Services Credentials
An Amazon Web Services cloud account requires
- Access key ID
- Secret access key
To create an access key:
- Log in to the Amazon Web Services console by using a power user account with read and write privileges.
- Navigate to Identity and Access Management (IAM) > Users > Security Credentials.
- Click Create access key.
Access keys are long-term credentials for an IAM user or the AWS account root user. You can use access keys to sign programmatic requests to the AWS CLI or AWS API (directly or by using the AWS SDK).
Access keys consist of the following parts
- Access key ID of 20 digits, for example, AKIAIOSFODNN7EXAMPLE
- Secret access key, for example, wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
Like a user name and password, you must use both the access key ID and secret access key together to authenticate your requests. Manage your access keys as securely as your user name and password. When you create an access key pair, save the access key ID and secret access key in a secure location. The secret access key is available only at the time you create it. If you lose your secret access key, you must delete the access key and create it again.
As a security best practice, you must regularly rotate (change) IAM user access keys. If your administrator granted you the necessary permissions, you can rotate your own access keys.
Amazon Web Services: Cloud Account
To create a cloud account:
1. Log in to the vRealize Automation console as Cloud Assembly Administrator.
2. Select the Amazon Web Services cloud account type
a. Access key ID
b. Secret access key
c. Name
3. Click VALIDATE, and
4. Under Configuration section
a. select the Amazon Web Services regions to deploy services
b. (optional) Select Create a cloud zone for the selected regions
5. (Optional) add capability tags
6. Click ADD
If the credentials are validated successfully, an extra option is available to select Amazon Web Services regions. Services requested by vRealize Automation are deployed to these regions. Cloud zones and projects can manage these regions.
After the cloud account is created, the data collection process starts immediately to gather resources from Amazon Web Services. Resources include images, flavors, machines, networks, security objects, and volumes.
Amazon Web Services: Simple Cloud Template
Drag components from the AWS section to the design canvas to create a cloud template. Deployed resources are hosted on Amazon Web Services.
Microsoft Azure
Microsoft Azure: Credentials
Log in to the Microsoft Azure console as an organization owner to gather information
- Subscription ID
- Tenant ID
- Client application ID
- Client application secret key
# How to obtain Azure credentials
1. Login to Microsoft Azure, navigate to Overview -> Subscription ID
2. Access Azure Active Directory
3. Navigate to App Registrations
a. Display Name (aka Client application ID)
b. Directory ID (aka Tenant ID)
Note:
The secret key can be generated by clicking the application.
Subscription ID - Allows you to access to your Microsoft Azure subscriptions.
Tenant ID - The authorization endpoint for the Active Directory applications that you create in your Microsoft Azure account.
Client application ID - Provides access to Microsoft Active Directory in your Microsoft Azure individual account.
Client application secret key - The unique secret key generated to pair with your client application ID.
Microsoft Azure: Cloud Account
To create a cloud account
1. Log in to the vRealize Automation console as Cloud Assembly Administrator
2. Navigate to Connections -> Cloud Account
3. Select the Microsoft Azure cloud account type
4. Enter the required information
a. Subscription ID
b. Tenant ID
c. Client application ID
d. Client application secret key
e. Name # Azure cloud account
f. Under Configuration
i. Region # Select the region for provisioning
ii. Create a cloud zone for the registered regions
# select and create the cloud zone
5. (optioin) Capability tags
6. Click ADD
If the credentials are validated successfully, an extra option is available to select Microsoft Azure regions. Services requested by vRealize Automation are deployed to these regions. Cloud zones and projects can manage these regions.
After the cloud account is created, the data collection process starts immediately to gather resources from Microsoft Azure. The resources include, images, flavors, machines, networks, security objects, and volumes.
Create Azure Clout Template
Drag components from the AWS section to the design canvas to create a cloud template. Deployed resources are hosted on Microsoft Azure.
Note:
When create the virtual machines and cloud objects, the actual objects are in Azure.
vRA create the references.
Google Cloud Platform
Google Cloud Platform - Credentials
A Google Cloud Platform account requires
- Project ID
- Private key ID
- Private key
- Client email
# How to generate the private key ID and private key
1. Log in to the Google Cloud Platform console as organization owner
2. Navigate to IAM & admin > Service accounts -> Edit the service account
3. Email # obtain the client email
4. Under Service account status
a. Click +CREATE KEY to generate the private key ID and private key
Note:
1. The project ID is available on the Google Cloud Platform console dashboard.
2. Clicking CREATE KEY, downloads a JSON file that includes all the required attributes,
including the project ID, private key ID, private key, and client email.
Store the file securely because this key cannot be recovered if lost.
You can generate a new file.
Google Cloud Platform: Cloud Account
To create a cloud account
1. Log in to the vRealize Automation console as Cloud Assembly Administrator
2. Navigate to Connections -> Cloud Account
3. Select the Google Cloud Platform cloud account type
4. click IMPORT JSON KEY to autofill the required fields
a. Project ID
b. Private key ID
c. Private key # SSL private key
d. Client email
5. Click VALIDATE
6. Name # enter cloud account name
7. Under Configuration
a. select regions to deploy services.
b. Create a cloud zone for the registered regions
# select and create the cloud zone
8. Click ADD
Create Google Cloud Platform - Cloud Template
Drag components from the GCP section to the design canvas to create a cloud template. Deployed resources are hosted on Google Cloud Platform.
VMwre Cloud Foundation
VMware Cloud Foundation delivers a natively integrated software-defined data center stack that includes core infrastructure virtualization, vSphere, vSAN, and NSX-T Data Center.
VMware Cloud Foundation also provides the following capabilities:
- Automated deployment and configuration of the VMware Cloud Foundation software components
- Life cycle management
- Supports traditional and new (cloud-native) workloads
- Enables the path to the hybrid cloud
SDDC Manager automates the entire system life cycle (from configuration and provisioning to upgrades and patching), and simplifies day-to-day management and operations. VMware Cloud Foundation supports automated deployment of vRealize Suite Lifecycle Manager. You can then deploy and manage the life cycle of the vRealize Suite of products (vRealize Log Insight, vRealize Automation , and vRealize Operations Manager) through vRealize Suite Lifecycle Manager. VMware Cloud Foundation 4.0.x provides a standardized and configured infrastructure for vSphere with Tanzu.
Note:
SDDC Manager is an appliance
SDDC Manager Integration
Before creating a VMware Cloud Foundation cloud account, we must integrate with SDDC Manager.
# Add SDDC integration to vRealize Automation
1. Navigate to Infrastructure > Connections > Integrations
2. Click +ADD INTEGRATION.
3. Select SDDC Manager
4. In Summary, enter the required information
a. Name # example, VCF-4.1-SDDC
b. In SDDC Manager Credentials
i. SDDC manager IP address/FQDN
ii. Username # SDDC manager admin user name
iii. Password
c. Click VALIDATE
d. Click ADD
# Edit the SDDC Manager integration
1. Select Workload Domains tab
2. Select the workload domain
3. Click ADD CLOUD ACCOUNT
# Create Cloud Account using the selected workload domain
We use SDDC Manager to perform administration tasks on the VMware Cloud Foundation system. SDDC Manager provides the user interface for the single point of control for managing and monitoring the VMware Cloud Foundation system and for provisioning virtual environments.
Clicking ADD in the Summary tab retrieves the workload and management domains hosted on VMware Cloud Foundation.
vRealize Automation supports integration only with VMware SDDC manager v4.1 and later.
The management domain is created by default during the VMware Cloud Foundation installation. The VMware Cloud Foundation software stack is deployed on the management domain. Each configured workload domain is added as a cloud account. Cloud accounts are used in vRealize Automation to configure the provisioning infrastructure. To create the cloud accounts, the workload domain must be active.
VMware Cloud Foundation: Cloud Account
The selected workload domain is used to create the VMware Cloud Foundation cloud account:
- One cloud account per workload domain.
- Create service credentials or use the existing credentials.
- Configure cloud zone and image or flavor mappings.
- Resources are deployed on the workload domain.
How to create VCF cloud account
# Method 1
1. When editing SDDC Manager integration, there are two tabs, Summary tab and Workload Domains tab
2. By selecting Workload Domains tab, then select the workload domain, click ADD CLOUD ACCOUNT
# This will create the cloud account for the selected workload domain
3. Name # Enter the name of the cloud account, example VCF-<Workload-domain-name>-CA
4. Workload domain # It shows the selected workload domain
6. SDDC Manager FQDN # It shows the SDDC manager created when create SDDC manager integration
5. Auto Configuration
Select "Use cloud foundation managed service credentials"
Note:
- Service credentials are automatically created on the vCenter Server system.
- These service credentials are used to validate the cloud account. Certificates are automatically accepted.
6. vCenter Server # It shows the vCenter server in used
7. vCenter username
8. NSX Manager # It shows the NSX manager in used
9. NSX username
10. Under Configuration section
a. Select "Allow provisioning to these datacenters" # Select the vCenter datacenter for provisioning
b. Select "Create a cloud zone for the selected datacenters" # Select to create cloud zone
11. Capability tags
# (optional) Enter the capability tag(s)
12. Click ADD
After creating the cloud account, we can open the cloud account and click Setup Cloud to configure the workload cluster and NSX-T Data Center by using Quick Start wizard. Configure image or flavor mappings and create a cloud template as we create for a vSphere cloud account. The resources are deployed on the workload domain defined in the cloud account.
VMware Cloud on AWS
VMware Cloud on AWS brings the VMware enterprise-class SDDC software to the Amazon Web Services (AWS) cloud with optimized access to AWS services.
VMware Cloud on AWS is an integrated cloud offering jointly developed by Amazon Web Services (AWS) and VMware. You can deliver a highly scalable and secure service by migrating and extending the on-premises environments based on vSphere to the AWS Cloud running on Amazon Elastic Compute Cloud (Amazon EC2). With the same architecture and operational experience on-premises and in the cloud, we can quickly derive business value from the VMware and AWS hybrid cloud experience.
VMware Cloud on AWS - Credentials
The VMware Cloud on AWS cloud account requires an API token.
# How to generate an API token:
1. On the VMware Cloud Services toolbar, click your user name and select My Account
2. Select API Tokens tab
3. In Generate a New API Token section
a. Token Name # enter the token name
b. Token TTL # default 24 months, you could change the period
4. In Define Scopes section # Scopes provide a way to implement granular access control
a. All Roles
b. Organization Roles # Select one or more organization roles
i. Billing Read-only
ii. Organzation Member
iii. Organization Owner
iv. Support User
5. OpenID # Select if required
# The OpenID scope requests and receives information about authenticated sessions and users of your app
6. Click GENERATE
You use API tokens to authenticate yourself when you make authorized API connections.
For security reasons, only the token name is displayed after you generate the token. The token credentials are not displayed. You can reuse the token by copying the credentials from this page. You can regenerate a token at any time.
VMware Cloud on AWS - Cloud Account
To create a cloud account
1. Log in to the vRealize Automation console as Cloud Assembly Administrator.
2. Navigate to Connections -> Cloud Account
3. Select VMware Cloud on AWS
4. On New Cloud Account window, under VMware cloud on AWS Server Credentials section
a. VMC API token
Enter the API token generate previously
5. Click APPLY API TOKEN
6. SDDC name
select the appropriate SDDC from the drop-down menu
7. vCenter IP address/FQDN # It automatically populates
8. NSX Manager IP address/FQDN # It automatically populates
9. vCenter username # enter the vCenter admin user name
10. vCenter password # enter vCenter admin password
11. Click VALIDATE
12. Name # enter VMware cloud on AWS name
13. Capability tags # enter capability tags (optional)
14. Click ADD
If the specified API token is validated, all the SDDCs from VMware Cloud on AWS are acquired. Selecting the appropriate SDDC autofills the vCenter Server IP address and the NSX Manager IP address.
Configure image or flavor mappings and create a cloud template as you create for a vSphere cloud account. The resources are deployed on the SDDC defined in the cloud account
Service Broker for Catalog Management
Using Cloud Assembly, we can create cloud templates and deploy services from cloud templates. Administrators can use Service Broker to create a catalog of services and enforce governance to users who consume resources from the self-service catalog.
Service Broker offers a single console where you can request and manage the catalog items from various platforms. For example, catalog items can be presented from Cloud Assembly cloud template, AWS cloud Formation Template, vRealize Orchestrator workflows and extensibility actions, code stream pipelines.
A Cloud Assembly user can create cloud templates.
We use Service Broker to ensure that the users are only able to consume and manage deployed resources.
As an organization administrator,
We create catalog items by importing the templates from various supported sources that the users can deploy to cloud vendor regions.
As the users,
they can request and monitor the provisioning process.
Self-Service Catalog
Cloud templates that are released to Service Broker are available in the self-service catalog. Members of the configured project can deploy services from the Catalog tab.
A catalog item is the specification for one or more machines, networks, and other components that we deploy to a cloud vendor.
The cloud administrator determines access to different items and where they can deploy them.
Releasing Cloud Templates
The Cloud Assembly cloud templates must be released for import into Service Broker. We can click RELEASE to release older version cloud templates. Alternatively, we can click VERSION and select the Release this version to the catalog check box to release the current draft.
# How to release cloud template
1. Select the cloud template, click Design tab
2. Navigate to the older version cloud template, and click RELEASE, or
3. On the latest/Current Draft, click VERSION to create a version and release to the catalog
a. On the Creating Version window
i. Version # enter the version number
ii. Enter information in Description, and Change Log
iii. In Release, click to select "Release this version to other catalog"
iv. Click CREATE
Note:
a. Released cloud templates have a check box,
and you can use UNRELEASE to remove a cloud template from the Service Broker catalog.
b. We can release the cloud template only if it is versioned.
Accessing Service Broker
Log in to the vRealize Automation console as a user with one of the assigned Service Broker roles. Based on the assigned role, a user can access Service Broker features.
# How to access Service Broker
1. Login to vRealize Automation
2. Select Services tab
3. Under My Services, and click Service Broker
One of the Service Broker roles must be assigned to view Service Broker in the My Services list. An organization role must also be assigned to this user:
- Organization Owner
- Organization Member
Content Sources
A content source defines the origin of importing the cloud templates into a Service Catalog. Only the released cloud templates from the selected project are imported. The imported cloud templates are listed under the Content section in the left pane.
# How to access Content Sources
1. Login to vRealize Automation console
2. Select Service tab, and click Service Broker
3. On Service Broker window, select Content & Policies tab
a. Catalog
b. Deployments
c. Content & Policies
i. Content Sources <------ Select Content Soruces
- AWS CloudFormation Template
- VMware Cloud Templates
- vRealize Orchestrator Workflow
- Extensibility Actions
- marketplace VM Templates - OVA
- Code Stream Pipeline
ii. Content Sharing
iii. Content
iv. Policies
v. Definitions
vi. Enforcement
vii. Notification
viii. Email Server
d. Infrastructure
e. Approvals
After we add the content source, templates are refreshed every six hours. Changes to templates in your external sources are reflected in the catalog after a refresh.
If we add a new template or change a template, and you must see the changes before a standard refresh, you can edit the content sources and click Save and Import.
When we delete a content source, the imported items are deleted from the catalog. But the Cloud Assembly cloud templates remain intact.
Content Sharing
We can use content sharing to make the imported cloud templates available to project members. Select the project whose cloud templates must be shared. Click +ADD ITEMS and select the released cloud templates.
# How to share content
1. In Service Broker console, select Content & Policies tab
2. On the left pane, select Content Sharing
a. Project # Enter the project name
b. Click +ADD ITEMS
Select the release cloud templates
Note:
1. Project members can deploy the shared templates from the catalog.
2. When sharing the content, there are two sharing options
a. Content Sources
b. All Content
Content Sharing - Options
Cloud templates can be shared in the following ways
- Content Sources: Dynamic method of sharing content. If new cloud templates are added to the content source, they are available in the catalog for members of this project.
- All Content: Static method of sharing content. If new templates are added to the content source, we add them individually to make them available in the catalog.
If we share Cloud Assembly cloud templates, the content list includes cloud templates that are associated with the selected project. The content list might also include cloud templates that are explicitly shared with other projects in the organization.
Policy Definitions
Policies are a set of rules or parameters that are applied to enable governance and process the deployments.
# How to configure policy definitions
1. In Service Broker console, click the Content & Policies tab
2. Navigate to Policies > Definitions
3. The following policy types are available
a. Approval Policy
b. Day 2 Actions Policy
c. Lease Policy
Note:
a. A policy that we create is applied to new deployments and to current deployments.
b. If we create a policy, wait for Service Broker to evaluate and process the policy.
Policy Type - Approval Policy
We configure an approval policy to have governance and control over deployment requests and day-2 action requests, such as Approve a deployment that consumes a large amount of resource, or approve the day-2 action of a deployment that many users consume.
# How to configure approval policy
1. In Service Broker console, click the Content & Policies tab
2. Navigate to Policies > Definitions
3. Select Approval Policy
4. In Approval policy window
a. Type # It shows Approval
b. Name # enter the name for approval policy, such as RHEL-Approval-Policy
c. Description
d. Scope
i. Organization # entire vRealize Automation organization
ii. Project # only for specific project, normally select project level
- If select Project level, then select the required project
e. Deployment criteria # we can set multiple levels of criteria
i. resources # we can set resources, or othe type
such as flavor
ii. has any
such as equals
iii. value
VMW-Large
f. Approval mode
i. Any
# Only one approver must approve the request before it is processed.
ii. All
# All approvers must respond with the same response before the request is processed.
If one approver rejects the request, the request is denied and the user is notified.
g. Approvals
Click +ADD USERS # to add the required approver
h. Auto expiry decision
i. Reject <--- normally we select Reject, when no approval has not been actioned
ii. Accept
i. Auto expiry trigger
<number> days
# The request for approval will automatically rejected after number of days
# if the deployment has not been approved
j. Actions
Select the action to perform
The Service Broker administrator is responsible for configuring an approval policy. Policies are applied to resources that are consumed by catalog users.
Scope: The scope determines if the policy is applicable to all deployments in this organization or to only deployments in a selected project.
Deployment Criteria: If we want to further refine when the policy is applied within the selected scope, we add a policy criteria. The policy criteria is a logical expression.
Approvers: Add the name or email address for each approver. The approval request is sent to all approvers at the same time.
An approver, who might not be a regular Service Broker or Cloud Assembly user, must have one of the following combination of roles:
- Organization member and Service Broker user
- Organization member and the Manage Approvals custom role
These roles provide the minimum level of permissions and still allow them to approve or reject a request.
# Auto expiry decision
Automatically approve or reject a request after the number of days specified in the Auto expiry trigger field.
• Approve: The request is approved if an approver does not respond in the amount of time specified.
• Reject: The request is denied if an approver does not respond in the amount of time specified.
# Auto expiry trigger
The number of days the approvers have to respond before the Auto expiry decision is triggered.
The value should be in the range of 1 through 7 days.
# Actions
Select one or more actions that the policy applies to.
The actions include deployments and component level day-2 actions.
Approval Requests
When a deployment or day-2 action request from a catalog user matches the approval policy criteria, the request is sent to approvers.
The catalog user must wait for the approvers to approve their requests. Users can monitor the approval request from their Approval tab.
All approvers receive an email notification with the approval details. The approver must log in to Service Broker and use the Approvals tab to accept or reject a request. The catalog user receives an email notification when the approver responds to a request.
# How to monitor or approve the deployment request
1. Login to Service Broker
2. Access the deployment -> Approvals tab
a. Catalog user (requester) can monitor the approval status
b. Approvers can approve or reject the request
Policy Type - Lease Policy
The lease policy enables administrators to control the number of time deployments are available to the users. If we do not have any lease policies defined, then the deployments never expire.
# How to configure lease policy
1. In Service Broker console, click the Content & Policies tab
2. Navigate to Policies > Definitions
3. Select Lease Policy
4. In Lease policy window
a. Type # shows Lease polcy type
b. Name # enter the name, such as REHL-Test-VM-30days-Lease
c. Description
d. Scope
i. Organization
ii. Project
- Select the project if the scope is set to Project
e. Deployment criteria
# The policy criteria is a logical expression.
f. Enforcement type
i. Hard # the deployment will be deleted when expired
ii. Soft
g. Maximum lease (days)
h. Maximum total lease (days)
i. Grace period (days)
Note:
When a lease policy is created or updated,
it continuously evaluates the deployments in the background to ensure that they comply with the defined leases.
Enforcement type: Enforcement is either hard or soft. Hard policies are ranked higher than soft policies. Hard policies override soft policies. If a conflict occurs between a soft lease policy applied to an organization and a soft lease policy applied to a project, the project lease policy takes precedence because it is more specific.
Maximum lease (days): The maximum number of days that a deployment can be active initially at the deployment time or when users extend a lease, for example, 30 Days.
Maximum total lease (days): In this scenario, the deployment is shut down after 30 days and an email is sent to the user. If the user does not extend the lease, the deployment is destroyed after 10 days. If the user extends the lease for 30 more days, and another 30 days, for a combined total of 90 days, the maximum lease time is reached and the deployment is shut down. The deployment is destroyed 10 days later, for example, 90 Days.
Grace period (days): The number of days after a lease expires before it is destroyed. This grace period allows users to extend the lease for another block of time that does not exceed the Total Lease value, for example, 10 Days.
Policy Type: Day 2 Actions Policy
Day 2 Action policies enable the administrator to control changes that users can make to deployments and their component resources. If you do not have any Day 2 Action policies defined, then no governance is applied, and all users have access to all the actions.
# How to configure Day 2 Actions policy
1. In Service Broker console, click the Content & Policies tab
2. Navigate to Policies > Definitions
3. Select Day 2 Actions Policy
4. In the Day 2 Actions policy window
a. Type # shows Day 2 Actions
b. Name # enter the name, such as RHEL-TEST-Day-2-Action-Policy
c. Description
d. Scope
i. Organization
ii. Project
- Select the project if the scope is set to Project
e. Deployment criteria
# The policy criteria is a logical expression.
f. Enforcement type
i. Hard
ii. Soft
g. Role
# We can entitle users to run actions based on roles. To grant certain action privileges to a role, we can create a policy for that role.
i. Administrator
Entitle the project administrators associated with the deployment to run the selected actions.
Administrators can also run any actions that their project members can run.
ii. Member
Entitle the project members associated with the deployment to run the selected actions.
iii. Custom Role
If we have one or more custom roles defined, we can select a named role in the list.
The users assigned to the role are entitled to run the selected actions on the deployments in their projects.
h. Action
Actions are cloud-specific. When you are entitling the users to make changes,
consider what cloud accounts the entitled users are deploying to and ensure that you select all the cloud-specific versions of the actions.
Monitoring Deployments
Requests can be monitored on the Deployments tab. Click the requested item to view the deployment details.
# How to monitor deployments
1. In Service Broker, select the deployment
2. Select Deployment tab
a. Catalog
b. Deployment <---- Select Deployable tab
c. Approvals
3. Click Topoloy
# To visualize the deployment structure and resources.
4. Click History
# Provisioning events and any events related to actions that you run after the requested item is deployed.
If the provisioning process fails, the History tab events help you with troubleshooting failures.
when integration vRealize Automation with vRealize Operations Manager, additional tabs are available, including Pricing, Monitor and Optimize.
Managing Deployments
A Service Broker user can manage the whole deployment with limited options. Click the deployment and select the object, then click ACTIONS to manage the object.
# How to manage deployments
1. From Service Broker console, select and click the deployment
2. In Deployments tab, select "..." on the left next to the deployment, select the available option
a. Change Lease
b. Change Owner
c. Delete
d. Edit Tags
e. Power Off
3. Select the object in Topology tab (Design Canvas), click ACTIONS
4. Select the available actions
a. If the object is an VM, then the available options
- Add Disk
- Change Security Groups
- Connect to Remote Console
- Create Snapshot
- Delete
- Power Off
- Reboot
- Reset
- Resize
- Resize Boot Disk
The options available for a Service Broker user to manage the deployment and its objects depends on the policies defined by the Service Broker administrator.
Request Forms
Service Broker offers the default form with minimal options. Administrators can use the Custom Form feature to customize the request form. Service Broker offers the Custom Form feature to customize the input parameters that are offered to a user at the request time.
# How to change/edit request forms
1. Login to Service Broker as administrator
2. Navigate to Content & Policies tab
3. Select Content
4. From the list of contents, click (...) left next to the content
a. Customize form
# Select and custom the request form
b. Customize icon
5. On the form design canvas, select/drag the icon/item from Generic Elements to the request form
Customize the request form
6. click ENABLE to activate the form
Note:
Content lists all the imported blueprints and templates
Drag elements to the design canvas and use the properties pane to configure each element. Activate the custom form to update the new request form.
The custom form design canvas has the following broad categories
- Elements pane: Drag various elements to the design canvas.
- Design canvas: Overview of items in the request form. You can change the order of listed items.
- Properties pane: The field properties in Service Broker determine the look of the fields and the default values that are presented to the user. You can also use the properties to define rules that ensure that the users provide a valid entry when they request the item from the self-service catalog. You configure each field individually. Select the field and edit the field properties.
— Appearance: You use the Appearance properties to determine whether the field appears on the form and the label and custom help are available to your catalog users.
— Values: You use the Values properties to provide any default values.
— Constraints: You use the Constraint properties to ensure that the requesting user provides valid values in the request form
vRealize Automation Extensibility
The extensibility techniques enable you to extend the capabilities of vRealize Automation beyond the built-in capabilities. Additionally, these extensibility techniques enable us to tightly integrate vRealize Automation with systems in our IT infrastructure such as IP address management systems, configuration management databases, and more.
Native Functionality in vRealize Automation
vRealize Automation is a multicloud cloud management platform with the several built-in capabilities:
- Deploy machines into VMware platforms such as vSphere and VMware Cloud on AWS.
- Deploy machines into third-party public clouds such as Amazon Web Services, Microsoft Azure, and Google Cloud Platform.
- Deploy machines controlled by configuration management tools such as SaltStack, Ansible, Ansible Tower, and Puppet.
- Deploy disks, networks, load balancers, and other services.
Overview of Extensibility
Extensibility is a collection of techniques that can be used to extend the built-in capabilities of vRealize Automation. Each of the extensibility techniques can use vRealize Orchestrator workflows or Action Based Extensibility (ABX) actions.
# Life cycle extensibility options
. Implementing DNS record changes
. IPAM solution
. Adding users and domain registration
. Executing PowerShell scripts
. Interoperability with third-party tools, such as ServiceNow
. Installation of software
. Actions for everyday operations, such as backups
# XaaS extensibility options
. Create custom actions
. Create services to be requested from the catalog
vRealize Orchestrator
vRealize Orchestrator leverages workflows to automate hardware and software systems throughout your IT infrastructure. vRO workflows are created using a visual, drag-and-drop programming approach. In addition, we can add code to vRO workflows to customize their behavior.
That code can be written in
1. JavaScript
2. Node.js
3. PowerShell, or
4. Python
vRealize Orchestrator supplies hundreds of built-in workflows, and additional workflows can be added by installing plug-ins.
vRealize Orchestrator is included with vRealize Automation. vRealize Orchestrator includes numerous preinstalled plug-ins. Additional plug-ins can be downloaded from VMware Marketplace.
ABX Actions
ABX actions provide multicloud Function as a Service (FaaS) capabilities to extend the capabilities of vRealize Automation and to integrate with your IT infrastructure.
ABX actions can be written in
1. Node.js
2. PowerShell, or
3. Python
ABX actions in vRealize Automation are like AWS Lambda. Both platforms provide Function as a Service (FaaS) capabilities, but ABX actions are multicloud. In vRealize Automation, you can run your ABX action on your on-premises vSphere environment, or on Amazon Web Services (AWS), or on Microsoft Azure.
In the example ABX action in the screenshot, the Python code is used to cause vRealize Automation to use a custom host name selected by the end user instead of the host name that vRealize Automation selects by default.
Defining vRO Workflows and ABX Actions
vRO workflows and ABX actions are defined in different locations in the vRealize Automation user interface.
vRealize Orchestrator workflows automate IT infrastructure processes. ABX actions provide an additional method for automation.
# How to define vRO workflows in the Orchestrator Client.
1. From the Cloud Services Console (vRA console)
a. Services <-----select Services tab
b. Identity & Access Management
c. Branding
2. Under My Services
a. Cloud Assembly
b. Orchestrator <----- Select Orchestrator
c. Code Stream
d. Service Broker
e. vRA Migration Assistant
3. On Orchestrator window
4. Select Library -> Workflows
# How to define ABX actions in Cloud Assembly
1. From Cloud Service Console (vRA console)
2. Select Services tab
3. Under My Services, select Cloud Assembly
4. Select Extensibility -> Library Actions
After defining vRO workflows and ABX actions, we can use both for extensibility operations in Cloud Assembly and Service Broker.
One way of using vRO workflows and ABX actions for extensibility in Cloud Assembly is by creating an event subscription.
# How to create an event subscription
1. From the Cloud Services Console (vRA console)
2. Navigate to Cloud Assembly > Extensibility > Subscriptions
We can configure Service Broker to enable users to call vRO workflows and ABX actions from the catalog. For vRO workflows and ABX actions to be available for use in Service Broker, we must create a content source for each.
# How to create content sources
1. From the Cloud Services Console (vRA console)
2. Navigate to Service Broker
3. Select Content & Policies -> Content Sources
Event Topics in vRealize Automation
vRealize Automation has many predefined event topics. Each event topic is linked to specified times during the deployment life cycle.
Event topics trigger when particular events occur in vRealize automation, such as when a machine is provisioned, when a cloud template is modified, and so on. By configuring a subscription, we can instruct vRealize Automation to invoke a specific vRO workflow or ABX action when a particular event topic triggers.
Note:
1. Many events are blockable
2. When we create the subscription, we can choose for vRealize Automation to invoke a vRO workflow or ABX action
a. synchronously (blocking) ,or
b. asynchronously (nonblocking)
3. If a particular event topic is not blockable, then we do not have that choice.
4. Nonblockable (asynchronously) event topics in a subscription always result in the specified vRO workflow or ABX action being called asynchronously.
5. Each event topic is defined by a publisher such as Blueprint, Provisioning, Kubernetes, and so on.
6. The publisher is the subsystem in vRealize Automation that defines and monitors event topics.
Each event topic displays a list of schema details when opened from the event topics list.
# How to view the list of event topics and event detail
1. In Cloud Assembly, access Extensibility
2. Select Library -> Event Topics
3. Click an event topic to view the details
4. The new window opens, and shows
a. Description # description of the event topic
b. Topic ID
c. Publisher # the publisher that defines the event topic
d. Blockable # shows whether the event is blockable or non-blockable
e. Parameters
# It shows the paramters will be defined on event topic
i. Key
ii. Data Type # such as string[], string
iii. Read Only # yes or no
iv. Description # description of the key
Note:
1. This page lists both the name of the event topic and its topic ID, and other information
2. The name of the event topic is a human friendly name
3. The event id is a
dotted notation
# The topic ID is particularly useful to understand when writing vRO workflows or ABX actions.
The list of parameters of the event topic, also called event topic schema.
# How do we use event topic parameters
1. Each event topic sends a
payload of information <----- We will use these payload of information
from the vRealize Automation Event Broker to
the vRO workflow or ABX action that you specify in your subscription.
2. Different event topics define the payload differently, examples
a. an array of the IP addresses that vRealize Automation is assigning to the NICs in the machines being deployed,
b. the ID of the cloud template being deployed,
c. the project that the end user belongs to, and
d. custom properties defined in the cloud template.
3. The communication between Event Broker in vRealize Automation and the vRO workflow (or ABX action) called is bidirectional.
a. vRealize Automation not only sends a payload to vRO (or ABX), but
b. vRO (or ABX) can send a payload back to vRealize Automation.
4. Some parameters are read-only
a. vRO workflow or ABX action will be able to see the data stored in that parameter, but
b. your vRO workflow or ABX action will not be allowed to change that value
About Subscriptions
Subscriptions are used to specify that when a particular event topic triggers, vRealize Automation should invoke a specific vRO workflow or ABX action.
By using a vRealize Orchestrator integration, or extensibility actions with vRealize Automation Cloud Assembly, you can create subscriptions to extend your applications.
Extensibility subscriptions allow you to extend your applications by triggering workflows or actions at specific life-cycle events. You can also apply filters to your subscriptions to set Boolean conditions for the specified event. For example, the event and workflow or action only triggers if the Boolean expression is 'true'. This is helpful for scenarios where you want to control when events, actions, or workflows are triggered.
Extensibility subscriptions in vRealize Automation 8.x work similarly to the subscriptions included in vRealize Automation 7.x. However, there are some key differences:
1. You cannot bind a workflow for all events anymore.
2. The conditions for running the subscription are now based on
JavaScript.
3. Subscriptions can be scoped to individual projects or configured to be shared across all projects in a given organization.
4. You can set a recover workflow in case the subscription workflow fails.
5. Timeout behavior is similar with some differences:
a. vRealize Automation uses a timeout for the workflows being started by Event Broker blocking subscriptions.
If a workflow run lasts more than the set timeout period, then it is considered failed by vRealize Automation.
b. In vRealize Automation 7.x, the default timeout value for all states and events is 30 minutes and is configured in the vRealize Automation global settings.
c. In both vRealize Automation 7.x and vRealize Automation 8.x a timeout value can be set at the subscription level.
Note:
The default timeout period in vRealize Automation 8.x is
10 minutes,
and that you should change the project request timeout if it is lower than the subscribtion timeout.
d. In vRealize Automation 7.x, it is also possible to configure individual state and event timeout values by changing configuration files in the IaaS server.
6. Priority defines the order of running blocking subscription where 0 means highest priority and 10 means lowest priority.
The default value is 10.
To select the most appropriate event topic, it is important to evaluate if the event is triggered at the right step of the process and if it carries the payload necessary to perform the extensibility operation.
The payload can be identified with selecting the different event topics.
The Read Only - No tag is used for properties that support both read and write operations. With read and write operations, it is possible to use a workflow output to set the property back in vRealize Automation. To do this, it is mandatory to set the subscription to be blockable. For more information on blockable extensibility subscriptions, see Blocking event topics in Using and Managing vRealize Automation Cloud Assembly.
# To set property back in vRA using a workflow output:
Mandatory: Set the subscription to the blockable (synchronously)
The following are some of the event topics support setting properties:
- Compute reservation is used to change the placement.
- Compute allocation is used to change resource names or hosts
- Compute post provision is used to after deployment resources are provisioned.
- Network configure is used to configure the network profile and individual network settings.
# Prerequisites
1. Verify that you have the cloud administrator user role.
2. If you are using vRealize Orchestrator workflows:
a. The library of the embedded vRealize Orchestrator Client or the library of
any integrated external vRealize Orchestrator instance.
3. If you are using extensibility actions:
a. Existing extensibility action scripts.
# How to create new subscription
1. Select Extensibility > Subscriptions
2. Click New Subscription
3. Enter the details of your subscription
a. Name # name of the new subscription
b. Description
c. Status
Toggle Enable/Disable subscription
4. Set the Organization scope for the subscription
5. Select an Event Topic. # such as
a. Compute allocation, or
b. Computer post provision, or
c. Netowrk configure
6. (Optional) Set conditions for the event topic.
Note:
a. Conditions can be created by using a JavaScript syntax expression.
b. Toggle Enable/Disable Filter events in topic
7. Under Action/workflow, select a runnable item for your extensibility subscription.
8. Blocking
Toggle Enable/disable "Block execution of events in topic"
9. Timeout
a. Min: 0 min
b. Max: 10
10. Recover action/workflow
Click +ADD to add recover action/workflow
11. To define the project scope of the extensibility subscription,
deselect Any Project and click Add Projects.
Note:
If the organization scope of the subscription is set to Any tenant organization,
the project scope is always set to Any Project and the project scope cannot be changed.
You can only change the project scope if the organization scope is set to the provider organization.
12. To save your subscription, click Save.
Results
Your subscription is created. When an event, categorized by the selected event topic occurs,
the linked vRealize Orchestrator workflow or extensibility action is initiated and all subscribers are notified.
Event Topic is used to specify exactly one type of event that vRealize Automation should look for.
The Condition toggle provides a code editor that you can use to specify the exact conditions that must be satisfied for vRealize Automation to invoke the vRO workflow or ABX action. Examples of conditions include a specific cloud template that is being deployed, a machine with a specific name that is being deployed, and so on. If you specify a condition in a subscription, then both the event topic must trigger and the condition must be met for vRealize Automation to invoke the vRO workflow or ABX action.
Action/workflow is used to specify which vRO workflow or which ABX action you want vRealize Automation to invoke.
The Blocking toggle allows you to indicate whether you want vRealize Automation to call the vRO workflow or ABX action synchronously (blocking) or asynchronously (nonblocking). If you specify blocking, you can specify a maximum amount of time that the vRO workflow or ABX action can run and a priority if multiple subscriptions exist for the same event topic.
Recover action/workflow allows you to specify a vRO workflow or ABX action to call if the vRO workflow or ABX action for the subscription fails. This other vRO workflow or ABX action is designed to gracefully address failures.
Subscription scope is used to control whether the subscription is limited to a single project or applicable to all projects.
vRealize Orchestrator Workflows
We start the vRealize Orchestrator Client, review the schema of the vRO workflow and create a subscription that calls a vRO workflow.
Orchestrator Client
Orchestrator client is used for developing, executing, debugging, managing, and monitoring vRO workflows.
There are a few specific areas are particularly useful to vRO developers:
- You can create, run, and debug workflows at Library > Workflows.
- You can create vRO actions at Library > Actions. Like functions in other programming environments, vRO actions are reusable snippets of code that can be called from any workflow. vRealize Orchestrator has hundreds of built-in vRO actions, and you can easily create your own custom vRO actions.
Note: vRO actions and ABX actions are unrelated.
- You can monitor running workflows at Activity > Workflow Runs. Additionally, a record of workflow runs is maintained so that historical information is available about workflows that ran in your environment.
- You can import packages created by VMware, third-party developers, and other vRealize Orchestrator environments at Assets > Packages. Additionally, you can easily create your own packages. Each package contains a collection of vRO workflows, vRO actions, configuration elements, and resources.
- You can explore all objects managed by the plug-ins installed in vRealize Orchestrator at Administration > Inventory.
- You can look up the details of the hundreds of data types provided by vRealize Orchestrator at API Explorer.
vRO client has the following tabs
1. Summary
# There are following actions can be performed when click on the available action icon
- Run
- Debug
- Schedule
- Validate
- All Runs
- Delete
2. Variables
3. Inputs/Outputs
4. Schema
5. Input Form
6. Version History
7. Audit
Orchestrator Client - Summary Tab
On the Summary tab, you set the general properties of a workflow, such as the workflow name, its version number, and its description.
1. Workflow name
2. ID # work flow ID
3. Version # update the version 0.0.0 three digits
4. Tags # it shows the existing tag in use, could also enter new tag
5. Groups # select a group
6. Folder # it shows the existing folder, or click Select Folder to change folder
7. Server restart behavior # Select drop down available behavior
i. Resume workflow run, or
other behavior
8. Resume workflow from failed behavior
i. System default # select drop down available behavior
# it concerns with what to do if the vRO workflow fails.
9. Description
ID is a read-only text field that reports the workflow’s workflow ID (not the related concept of a workflow run ID). Workflow IDs are handy when using the vRO REST API to invoke workflows external to the Orchestrator Client.
We can create multiple versions of a workflow in the Versions text box. This mechanism enables you to compare versions side by side and revert to other versions.
The Tags text box enables us to organize workflows. Tags allow us to label our workflows. We can use these tags for performing searches for workflows.
Groups enables us to control access to workflows. Groups and roles are more effective when we license vRealize Orchestrator with a vRealize Automation license than with a vSphere license.
Folder provides another way to organize your workflows. Folders enable us to organize workflows hierarchically like files in a filesystem. We can use tags and folders together.
Server restart behavior enables us to control how vRO handles running workflows if the vRealize Orchestrator server stops unexpectedly. The default behavior is that when the server is restored, vRealize Orchestrator automatically resumes (not restart) workflows from where they were. vRealize Orchestrator uses checkpointing to make this possible. You can optionally disable this feature on an individual workflow basis.
Orchestrator Client: Inputs/Outputs Tab
Inputs allow us to prompt whoever (or whatever) is calling our workflow for information.
Outputs allow us to pass information back to whoever (or whatever) is calling our workflow.
# Inputs/Outputs tab
- View, edit, and create inputs and outputs for our workflow
- Click New, to create new input/output
Properties of an input/output
1. Name
2. Type
# example types
a. Properties
b. Array/string
3. Direction
a. Input
# enable the user calling your workflow to feed information into the workflow.
b. Output
# pass information from the workflow back to the user.
4. Description
5. References
Each input and each output can be assigned a different type such as string, number, Boolean, and so on. The API Explorer enables us to look up all the data types defined by vRealize Orchestrator and the plug-ins.
We must specify a description for every input and every output so that other vRO developers can quickly and easily understand their purpose.
Orchestrator Client - Schema Tab
On the Schema tab, we define the logic that controls the behavior of the workflow.
1. The left side of the Schema tab includes all the schema elements that we can build into the workflow.
These elements include actions, decisions, numerous schema elements to call other workflows, and more.
# Schema elements (similar to clould templete desgin components), such as
a. Generic
Scriptable task, Decisions, Decision activity, User interaction,
Waiting timer, Waiting event,
End workflow, Throw execution, Workflow,
Action element, Workflow element, Foreach element,
Asynchronous element, Schedule workflow, Nested workflows,
Default error handler, Switch
b. Basic
c. Log
d. Network
2. The middle of the Schema tab includes the design canvas to which we drag the schema elements from the left side of the page.
3. The right side of the Schema tab enables us to configure the schema elements that we dragged to the design canvas.
4. SAVE, VERSION, CLOSE
# we save or create new versioni of the orchestrator workflow
Orchestrator - Subscriptions
We can use the vRO workflow by calling it from a subscription.
# How to create a subscription
1. In Orchestrator client, navigate to Subscripton -> New Subscription
2. Enter details of the subscription
a. Name # enter name of subscription
b. Description
c. Status
Toggle to enable/disable subscription
d. Event Topic # Change or edit the event topic
# Event topic, such as Compute allocation
i. Blockable # Yes
ii. Publisher # provisioning
iii. Parameters
iv. CHANGE # change the event topic
e. Condition
Toggle to enable/disable Filter events in topic
f. Action/workflow
# View and change the workflow
i. Type # Action based extensibility
ii. Project
iii. CHANGE # change the action/flow
g. Blocking
Toggle to enable/disable Block execution of events in topic
h. Timeout # minutes
i. Priority # 0, to required number
j. Recover action/workflow
Click +ADD # to add recover action/workflow
k. Subscription scope
Any project # Toggle to enable or select required project
Other options to use the vRO workflow include:
1. Creating a custom resource
Creating a custom resource enables us to create another component that we can drag to your cloud template.
2. Creating a catalog item in Service Broker
Set it up as a catalog item in Service Broker.
Packaging vRO Workflows
vRO workflows can be imported and exported between vRealize Automation environments.
# How to export vRO workflow
1. In Orchestrator client, expand Library -> Workflows
2. Navigate and click the workflow
3. In the workflow (design canva) window, on the top menu icon
a. All Runs
b. Delete Run
c. Run Again
d. Debug
e. Export <--- Select export to export the workflow
4. On the Confirm Export window, select any of the option
a. Add configuration attribute values to package
b. Add configuration secure string attribute values to package
c. View Contents
d. Add to package
e. Edit contents
ABX Actions
https://blogs.vmware.com/management/2020/09/vra-abx-flow.html
Extensibility has a long history within VMware’s Automation and Operations suites. Extensibility has traditionally been defined as how we create interactions with platforms outside of our management platform. Some of the most common examples:
- Interacting with IPAM Systems (Infoblox, BlueCat, etc)
- Pushing records into Configuration Management Databases (CMDB’s)
- Creating Records in DNS
- Interactions with various REST platforms
In vRealize Automation, we have refined the existing and introduced new extensibility capabilities in the platform.
# How to create & import ABX Actions and Flow
1. Login to vRA -> Assembly -> Extensibility
2. Go to Library -> Actions
3. Select NEW ACTION
4. On New Action window
a. Name # Name of ABX action
b. Description
c. Project # Select an existing project
d. (optional) Select Share with all projects in this organization
5. Click Next
6. You will be presented with the default ABX editor, by default you are in Type:Script
7. Select the script type
a. PowerShell
b. Python
c. Node.js
8. On top menu icon
a. Settings
b. Create Version
c. Delete
Note:
The code that implements the ABX action can be written in PowerShell, Python or Node.js
ABX Action Settings
We configure numerous settings that control the behavior of the ABX action on the right side of the New ABX Action wizard.
The value in the Main function text box defaults to handler.
Note:
vRealize Automation assumes that the name of the function that implements your ABX action is handler.
If you name your function other than handler, you must set the value in the Main function text box to what your function is called. Another use case for setting the value in the Main function text box is if your ABX action includes multiple functions. Only one of these functions is the entry point to your ABX action. You must set the value in the Main function text box to indicate the name of the entry point function.
Note:
The Default inputs option is useful when your ABX action is not being invoked by Event Broker.
If your ABX action is being invoked by Event Broker, then Event Broker sends a payload to your ABX action. If you click TEST to test your ABX action, then your ABX action is not being called by the Event Broker and therefore your ABX action is not going to receive the payload. In general, ABX actions are designed based on the assumption that they will receive the payload from Event Broker. To make testing possible, you can set Default inputs to pass the sort of values that you expect the payload to include.
Note:
If you set Default inputs and your ABX action is called by Event Broker,
then values included in the payload override the default inputs.
# ABX Action Settings
1. Main function # name of main function
2. Default input # name, value pairs
a. Name
b. Value
3. Dependency
Note:
a. vRealize Automation runs your ABX script code in a container.
b. If your code depends on libraries or packages not included in the container,
you can specify the needed content by setting a value in Dependency.
4. FaaS provider # specify where you want your ABX action script to run
a. select drop down option
i. On Prem
ii. AWS
iii. Azure
b. (optional) Set custom limits and retry options
4. Memory limit (MB)
5. Timeout(s) # timeout in seconds
6. (optional) Select Retry on failure
# instruct vRealize Automation to retry the ABX action if the ABX action fails
ABX Flows, ABX REST Calls, and ABX Scripts
In addition to ABX action scripts, vRealize Automation also enables you to create ABX REST calls and ABX flows.
REST request and REST poll allow you to invoke a REpresentational State Transfer (REST) operation once or periodically, respectively. Numerous VMware products and third-party products support REST operations.
1. In ABX action editor, click Script drop down opton, select
a. Flow
b. REST request
c. REST poll
d. Script
# create an ABX action that calls code that you write.
This code can be written in PowerShell, Python, or Node.js.
ABX Action Templates
Templates accelerate the development of ABX actions. you can base your ABX action on one of the templates provided by vRealize Automation.
In ABX Action design canvas, click LOAD TEMPLATE
Packaging ABX Actions
ABX actions can be imported and exported between vRealize Automation environments.
1. In ABX actions window
2. On the top menu icon
a. New Action
b. Import
c. Export
i. Select the ABX action, and click Export
ii. Browse to the location and save the exported ABX action
d. Delete
Subscriptions
One way to leverage your ABX action is to call it from a subscription. Other options include
1. Creating a "custom resource"
We can create a "custom resource" that calls the ABX action.
Creating a custom resource, in effect, allows us to create another component that we can
drag into the cloud template.
2. Creating a catalog item in Service Broker
Set it up as a catalog item in Service Broker
vRealize Automation Code Stream
DevOps must provide a continuous pipeline of rapidly delivered, high-quality applications and services.
vRealize Automation Code Stream provides a powerful set of tools to vRealize Automation to enable you to create DevOps pipelines and manage them. It offers a single-resource interface to deploy infrastructure, integrate repositories, and enable code with governance and auditing capability.
vRealize code stream
Pipeline Automation
Relase Dashbord
Reporting
vRealize code stream or vRealize Orchestrator Plugins:
Repositories & Source Code Management
Git, nuget, yum, perforce, Nexus
Continous Integration (CI)
Jenkins, Visual Studio, Bamboo, TeamCity
Testing Frameworks
Selenium, SoapUI, SonarQube, Jmeter
Provisioning & Configuration Mgmt
vRA, docker, puppet, Chef, SaltStack
Change Management
bmc, servicenow
Issue Tracking
Jira, Rally, Bugzilla
vRealize Automation Code Stream is included in the vRealize Automation Enterprise license and deploys with vRealize Automation. It integrates with many other applications for a full development stack option and it enables an administrator to integrate into Docker or Kubernetes directly and deploy custom pipelines designed to customize a full deployment from the same user interface.
DevOps
The term DevOps is derived from a combination of software development (Dev) and IT Operations (Ops). Companies are constantly developing applications. The application is tested, released, deployed, used, analyzed, and pulled back into the cycle for the next upgrade and improvement.
# Dev
Capture App Requirement (Plan) -> Generate YAML Blueprint (Code) -> Commit to version control -> Deploy the blueprint (Build) ->
Deploy and Test the blueprint (Test) --->
# Ops
-----> Release -> Deploy (Deploy the published blueprint version) -> Operate (vRealize Operations) -> Scale Deployment ->
Monitor (vRealize log Insight & vRealize Network Insight) --> Back to DevOps cycle
Continuous Integration / Continuous Delivery
Continuous Integration / Continuous Delivery (CI/CD) is the primary purpose of vRealize Automation Code Stream:
- Continuous integration: A three-step process for building, testing, and merging new builds or software code.
- Continuous delivery: Allows automatic releases to repositories.
- Automatic deployment: Covered by the addition of Kubernetes and the update processes.
New Applications can be automatically deployed onto production systems after they are tested and the code is released. Automatic deployment is a vRealize Automation Code Stream feature that can be built in to a pipeline.
vRealize Automation Code Stream Pipelines
vRealize Automation Code Stream uses pipelines to implement CI/CD
- A pipeline is a continuous integration and delivery model of your software release process.
- A pipeline is a sequence of stages with tasks that represent the activities in your software release cycle.
- Endpoints allow the tasks in your pipeline to connect to data sources, repositories, and notification systems.
# Example of code stream pipeline
1. Deploy VM and add IP to DNS
a. Deploy VM (VMware cloud template) -> next pipleline (Sequential task)
b. Change hostname (ssh command)
c. Add IP to DNS
# this task can be parallel task to "change hostname" or sequential task to change hostname
2. Install Software # After deploy VM and add IP to DNS, continue to install software
a. Request Approval # request approval for software installation
b. Server Online test # Powershell (other script type) to test the server
c. Install Software
# All these tasks are sequential tasks
vRealize Automation Code Stream has various use cases, such as
- Repeatable Kubernetes deployments
- Customization scripts
- Updating rolling updates to production
- Rapid deployment of testing applications
- Integration with notifications to tasks Integration with PowerShell
- API and SDK management in and out of deployments
- Testing and updating images for testing of hardware changes and updates
Infrastructure Pipelines
Infrastructure pipelines are designed to implement the back-end infrastructure. This infrastructure can include containers, virtual machines, and networking devices.
# Example of infrastructure pipeline
1. Create virtual machine
a. Collect from GIT
b. (Sequential task)
- Build Image
- build image2
c. Attach disk (sequential task to add more disk)
2. Network
a. Create load balancer
b. Expose 443 (sequential task)
Software Pipelines
Software pipelines allow direct integration of many deployment tools.
# Exmple of software pipelines
1. Setup script database
a. Connect to rest client
REST method
b. (sequential task)
- Run config (PowerShell)
- Setup DB (PowerShell)
c. Run PowerShell Script (other configuration)
Note:
When add either parallel task or sequential task, from the select task type drop down list,
we could select from the list of the supported softwares and options
- VMware cloud template
- CI
- Condition
- Custom
- UserOperations
- Pipleline
- Kubernetes
- Jenkins
- REST
- POLL
- PowerShell
- vRO
- TFS
- Bamboo
....
The core principle of CI/CD is that you continuously go through a process that includes developing code, deploying code, testing code, and improving or adjusting your code before the next deployment. A software pipeline helps to automate this process.
Integration with Repositories
Repositories store, share, and manage code among multiple developers. The most common repository system in use is based on Git. Git includes GitHub, GitLab, GitHub-Enterprise, GitLab-Enterprise, Bitbucket, and Bitbucket-Enterprise.
Other repository systems that can be integrated with vRealize Automation Code Stream include Bamboo, Gerrit, and Docker Registry.
# Create a git repository
1. Project # associate with a project
2. Type # GIT
3. Name # Test-GitLab
4. Description
5. Mark restricted
Toggle "non-restricted"
6. Git server type # select from drop down list
a. Gitlab-enterprise
7. Repo URL # https://<repo-url>
8. Branch
a. master
9. Authentication type # Select from drop down list
a. Private token
10. Username
11. Private token
12. SAVE, VALIDATE, CANCEL
Adding repositories to a build allows administrators to test new builds, verify functionality, and post new images seamlessly. If issues occur, you can destroy the new build without affecting the overall workflow.
Endpoints in vRealize Automation Code Stream
The endpoint types for vRealize Automation Code Stream differ from many of the endpoints for vRealize Automation. The vRealize Automation Code Stream endpoints
- Focus on CI/CD systems
- Can also provide load balancing
# Create new endpoint
1. Project # select project for the code stream endpoint
2. Type # select from drop down list
- Bamboo
- Docker
- Docker Registry
- Email
- Gerrit
- GIT
- Jenkins
- Jira
- Kubernetes
- TFS
- vRO
3. Name
4. Description
5. Mark restricted
Toggle "non-restricted"
6. Create/Cancel
vRealize code stream Pipeline Life Cycle
vRealize Automation Code Stream has a built-in Guided Setup Diagram to help you create the code stream pipeline. Steps include setting up endpoints, creating a pipeline, and monitoring executions through various dashboards that can be customized for different scenarios.
# Guided Setup Diagram
1. Add Endpoint
2. Create Pipeline
3. Run Pipeline
4. Manage Executions
5. View View Dashboards
Click CONTINUE
We can return to the guided setup program throughout the application from the top-right of the screen. Clicking the respective boxes opens the selected page in the application.
vRealize code stream interface - Navigation Bar
The vRealize Automation Code Stream interface has all tabs available in the left pane.
# The left pane is divided into three sections
1. Dashboards, Executions, User Operations, and Pipelines
# This section enables us to view statistics, monitor executions, and create and manage pipelines
a. Under Dashboards
- Last Viewed
- Pipeline Dashboards
- Custom Dashboards
2. Custom Integrations and Configuration
# This section controls the configuration of vRealize Automation Code Stream.
we configure endpoints to other systems like Kubernetes clusters, Cloud Assembly, and vRealize Orchestrator.
a. Under Configure
- Projects
- Endpoints
- Variables
3. Triggers
# This section is used to automation systems for tasks such as ticketing and using Git repositories
- Gerrit
- Git
- Docker
Code stream endpoints
Code Stream endpoints are associated with Cloud Assembly projects. When we add an endpoint, a drop-down menu enables us to specify the Cloud Assembly project. When we add an endpoint, the panel that appears is based on the type of endpoint.
Endpoints can also be imported and exported to quickly change the assigned project. Depending on the restricted value, the projects that the endpoint is allowed to be used in are isolated. If we want to set up restrictions but allow the same endpoint, we can duplicate the endpoint in both projects for metric needs.
Endpoints can be restricted. A restricted endpoint can be modified or deleted only by users with the Administrator role.
When a user who is not an administrator attempts to run a pipeline that includes a restricted resource, the pipeline stops at the task that uses the restricted resource. Then, an administrator must resume the pipeline.
# Example of email type end point
1. Project # end point assicated project
2. Type # select from the list
a. Email
3. Name # end point name
4. Description
5. Mark restricted
Toggle (non-restricted)
6. Sender's address
7. Encryption method
8. Outbound host
9. Outbound port
10. Outbound protocol
11. Outbound username
12. Outbound password
Custom Integrations
Administrators can set up custom endpoints by using Python2/3, Shell, or NodeJS. By using these tools, we can establish connections to nonconventional endpoints such as Slack, or even applications being created from the pipelines.
Custom integrations have the following requirements
- We must establish an endpoint URL or IP address.
- We need authentication established in the script.
- We need the supported API commands or script sets.
These connections require application support from the scripting language. So endpoint connections vary depending on the language.
The most common interfaces to use are SDK and API protocols. Using SDK or API protocols is helpful when implementing messaging systems or passing notifications to specialized systems such as Change Request Systems.
Sometimes we can establish protocols to a built system to further manage a pipeline deployment. This tool can be used as a Day 2 management tool instead of Orchestration workflows if needed.
Code stream Pipelines
Pipelines are the equivalent of blueprints in Cloud Assembly. Pipelines can run complex systems with tasks running either in parallel or sequentially
# Code Stream pipeline design canvas
There are four tabs on the top menu
1. Workspace
2. Input
3. Model <-- Click Model tab to work on UI
# work on parallel task, or sequential task
4. Output
Pipeline Flow
Pipelines are built of stages and tasks:
- Stages help break down the logical separation of tasks for ease of rollback and management.
- Tasks can run sequentially or in parallel.
- Parallel tasks in the same stage run simultaneously
The usage of stages also enables quicker and cleaner rollback procedure. Each rollback task is assigned to a stage.
Each task can also call other pipelines. So a pipeline can be nested.
Variables and Inputs
vRealize Automation Code Stream allows three types of inputs. Inputs include information that is either entered by the user when the pipeline is run or captured from other source (such as GitLab).
Variables can be used to pass information between multiple tasks and stages. Click SAVE often to update values. We can edit only one item (stage, task, or input) at a time, and we must click SAVE before we switch to another task. Password values are encrypted and do not appear in the logs.
If we require additional field types, they can often be passed directly in the YAML or script supplied in the pipeline itself. Only users with the Administrator role can view and modify restricted inputs and variables.
# Code stream input types
1. Regular
2. Secret
3. Restricted
From variables, we can see all the variables.
Each variable has following association
1. Project
2. Name
3. Type
a. Regular
b. Secret
c. Restricted
4. Value
5. Description
vRealize Automation Code Stream Roles
Roles control access in vRealize Automation Code Stream.
# vRealize Automation Code Stream has several roles
--------------------------------------------------------------------------------------------------------------
Access Level Administrator Developer Executor Viewer User
vRA Code Stream All Actions All: Restricted Execution Read-only None
service level actions
access
--------------------------------------------------------------------------------------------------------------
Project Admin All Actions All: Restricted All: Restricted All: Restricted All: Restricted
--------------------------------------------------------------------------------------------------------------
Project Member All Actions All: Restricted All: Restricted All: Restricted All: Restricted
--------------------------------------------------------------------------------------------------------------
Project Viewer All Actions All: Restricted Execution actions Read-only Read-only
All: Restricted means that this role has permission to perform create, read, update, and delete actions on entities except for restricted variables and endpoints.
Users with the Service Viewer role can see all the information that is available to the administrator. If users are affiliated with a project, they have the permissions related to the role.
Adding a repository
Several types of repositories, such as YUM or GitHub, can be integrated with several systems at once.
The internal Kubernetes repository can also be used. Images can be stored and used directly from Kubernetes or from a URL.
For GitHub, the repository has a user name and password, certificate, and bearer token options for authentication. Multiple branches and repositories are available in GitHub.
After a repository option is added, the pipeline can call specified images directly from the repository to place into Docker or Kubernetes.
# How to add a repository
1. In vRA code stream interface, navigate to Confgure -> Endpoints
2. Add new endpoint
3. New endpoint
a. Project # enter the associated project
b. Type # select from the drop down option
- GIT
c. Name # enter the name of the repository end point
d. Description
e. Mark restricted
Toggle "non-restricted"
f. Git Server Type # select from the drop down list
- GitHub
g. Repo URL # enter the repo url
h. Branch # enter the branch
master
i. Authentication Type # select from the drop down list
- Password
j. Username # enter user name
k. Password
4. SAVE, VALIDATE, CANCEL
Building Pipelines
Creating pipelines has multiple components, including stages and tasks.
You can create a single pipeline that can access multiple endpoints and run complex tasks:
- Workspace: Enables the naming of host endpoints, image builder locations, and limiting CPU and memory.
- Inputs and outputs: Designed for collecting user data during a pipeline run and outputting variables to various systems and pipeline tasks.
- Stage deployments: Provides a logical order of processes and systems to the developer.
- Sequential task: An individual code block is assigned to each stage. You can have more than one task per stage.
Kubernetes has base options for creating YAML files for get, create, apply, delete, and rollback. Each option directly correlates to the kubectl equivalent.
YAML files can be stored in a repository, such as GitHub, or in a local definition onscreen. Inputs open an Input text box during a run. Outputs can be defined in a YAML file and are replaced during runs. Sequential runs start one task at a time while parallel tasks can run at the same time. Notifications are sent to log, and rollback tasks are designed during a failed run to clean up partial deployments.
Notifications
Notifications enable you to put detailed notices through email, tickets into Jira, custom webhooks to notify about failures, or send successful details to the user.
Notifications are based per stage. To create a notification, you select the stage, and select the notification bar on the top-right panel.
Jira tickets are only available for failures. Webhooks are based on postpublish or update in REST formatting.
Entering $ in a text box generates a variable selector to select form inputs or properties in the pipeline, but variable lists do not appear to autoselect.
# How to configure Notification
1. Type # select one of the following type
a. Email
b. Ticket
c. Webhook
2. Event # select one of the events
a. On Pipeline Completion
b. On Pipeline Waiting
c. On Pipeline Failure
d. On Pipeline Cancellation
e. on Pipeline Started
3. Email server: # on the drop down selection, select the email server
4. Send Email
a. To # email IDs of recipients
b. Subject
c. Body
Roll back failed stages
The Rollback procedure is a tool to build custom pipelines to revert individual stages.
Individual rollback pipelines can be attached to each individual task, or to the stage itself. For simplification, we must create tasks with continue on failure enabled on the rollback so that it can verify if all elements are created.
Administrators can also use get functions and run conditions to validate if elements were created in both Docker and Kubernetes.
Individual task rollbacks can be more granular to speed the process but will require more pipelines to be generated.
# How to access task or stage rollback
1. In code stream UI, select the stage or task
2. On the right property window, select Rollback
Note: There are Notification, Rollback icon
Terraform with vRealize Automation
Infrastructure as Code (IaC) is the process of managing and deploying computer systems and architectures by using code files. These code files are both human-readable and machine-readable. IaC tools can create an exact architecture of networks, storage, resources, and systems based on code.
There are two approaches to IaC languages and these are Imperative and Declarative.
- An Imperative language is where you define the steps to be performed in your code, to achieve a given result. Examples of this include PowerCLI, vRO / JavaScript and Python.
- A Declarative language is where you define what end result you want, and not the exact steps or the ‘how’. Examples include Terraform, Ansible, Puppet, Chef, PowerShell DSC.
Terraform is an IaC product that can be used by vRealize Automation to manage other systems. You can also use Terraform to manage and create vRealize Automation configurations.
Most IaC code systems are like YAML formatting.
Infrastructure as Code (IaC) is a key part of DevOps. DevOps approaches the development of applications as a cycle of design, write, deploy, test, use, review, and repeat. A critical part of DevOps is to ensure that the development environment, the testing environment, and the production environments are identical. The IaC methodology is used to ensure that these environments are separate, yet identical in configuration.
DevOps and IaC
IaC must be included in many phases of DevOps:
- DevOps requires IaC
- The infrastructure used for development, the infrastructure used for testing, and the infrastructure used for production must be identical for the application that is being developed and managed by DevOps to work the same in all three environments.
- All these environments must be physically separate environments.
1. Using IaC is the only way to ensure that the infrastructures are identically configured.
2. Kubernetes is heavily used in DevOps because Kubernetes can decouple the infrastructure from the physical environment.
Terraform
https://registry.terraform.io/providers/vmware/vra/latest/docs
Terraform OSS is an open-source, free and simple executable file. It enables you to write your Infrastructure as Code in the HashiCorp Configuration Language (HCL). The real value from Terraform comes with the integration with providers. Today there are over 200 provider integrations including vSphere, AWS, Azure, GCP, K8s, Datadog, Grafana, F5, MongoDB, Artifactory, GitLab available on the Terraform Registry.
Terraform is an IaC system developed by Hashicorp
- Terraform relies on plug-ins called providers to interact with remote systems.
- Terraform configurations must declare which providers they require so that Terraform can install and use them.
- Hashicorp maintains providers for public cloud and vSphere at the Hashicorp Registry.
- Verified providers, which are supported and maintained by VMware, are available for vSphere, NSX-T Data Center, vRealize Automation, and other VMware systems.
- vRealize Automation can also use other Terraform providers for most other systems including Microsoft Azure, AWS, GCP, AD, Cisco, and Kubernetes.
Terraform Providers
https://registry.terraform.io/browse/providers
https://blogs.vmware.com/management/2020/01/getting-started-with-vra-terraform-provider.html
Providers are a logical abstraction of an upstream API. They are responsible for understanding API interactions and exposing resources.
Note:
1. Some providers require configuration (such as endpoint URLs or cloud regions) before they can be used.
2. We must first configure the prerequisites in vRealize Automation to manage Terraform.
Advantages of Using vRealize Automation to Manage Terraform
Using vRealize Automation to manage Terraform has multiple advantages:
- Terraform configurations can be combined with VMware Cloud Templates.
- The vRealize Automation Code Stream pipelines can leverage VMware Cloud Templates which contain Terraform configurations.
- vRealize Automation can enforce provisioning policies (lease, approval, cost, and so on).
- vRealize Automation can apply day-2 actions on deployments that contain Terraform configurations.
- VMware cloud templates that use Terraform configurations can be offered in the Service Broker catalog.
- You can run extensibility actions (ABX) and vRealize Orchestrator workflows against deployments with Terraform configurations with event-based subscriptions.
Running Terraform
vRealize Automation automatically deploys Terraform in a Kubernetes pod for use with Terraform configuration files.
1. Terraform configuration files (*.tf) plus other files store in the repository
a. GitLab Server
- GitLab
- GitLab Repository
b. GitHub
- GitHub
- GitHub Repository
2. vRealize Automation
# vRA integration with Git repository
# the Terraform configuration files
- Pull, and
- Push
# vRA integration with Kubernetes and Terraform
a. vRA deploys Kubernetes cluster
i. Terraform Deployment
- Terraform Namespace
ii. vRA pushes Terraform configuration files to Terraform
3. Kubernetes Cluster
a. Kubernetes cluster obtains the latest Terraform
https://projects.registry.vmware.com/vra/terraform.latest
b. It configure Terraform Namespace with the latest verion of Terraform
vRealize Automation does not need an external Terraform server to use Terraform configuration files
- We obtain the Terraform configuration files from a Version Control Server (VCS) such as GitLab, GitHub, or Bitbucket.
- vRealize Automation installs a copy of Terraform in a Kubernetes pod.
- Terraform configuration files are version-specific.
- Each time we use a Terraform component in a cloud template, we can specify which version of Terraform it should run on.
Requirements for Terraform Integration
To integrate vRealize Automation with Terraform
- Prepare a Kubernetes cluster.
- Configure a Terraform runtime integration that uses the Kubernetes cluster.
- Configure and enable the Terraform versions that we will use.
- Enable Terraform cloud zone mapping for the project.
- Configure a Version Control Server (VCS) project repository for Terraform configuration files.
These steps are required for vRealize Automation to use Terraform to manage and configure infrastructure. These steps are not needed if you plan to use Terraform to manage a vRealize Automation configuration.
Note:
1. The Kubernetes cluster must be prepared first.
a. Kubernetes cluster can be either a managed Kubernetes cluster, or
b. an external Kubernetes cluster
2. The other requirements can be done in any order.
3. Project repository, can be any Version Control Server (VCS), such as
- GitLab
- GitHub
- Bitbucket
Configuring a GitLab Project Repository for Terraform Configuration Files
IaC requires a version control system:
- The vRealize Automation Terraform integration requires the use of a version control system for the IaC configuration files.
- vRealize Automation uses the GitLab system.
- Begin by setting up a regular GitLab integration in vRealize Automation.
# How to setup Gitlab integration
1. create a Gitlab integration
Infrastructure tab -> Connections -> Integrations
2. In Gitlab integration window, there are three tabs
a. Summary
b. Projects
c. History
3. Summary tab
a. Name # name of Git repository, such as Test-Gitlab-Terraform
b. Description
c. GitLab Integration
i. Server URL # populated Gitlab server URL
ii. Token
# You must create an access token in GitLab for the user account that controls the repository ,
that vRealize Automation will connect to
- VALIDATE # click validate to ensure successful
d. Capabilities
i. Capability tags # enter capability tag(s) key:value pairs
4. SAVE/CANCEL
Note:
We can use any Version Control Server (VCS) such as GitLab, GitHub, or Bitbucket
We can use the same GitLab server for multiple purposes. A single server can serve vRealize Automation for Terraform configuration files, VMware Cloud Templates, and ABX actions.
We can also create multiple GitLab server integrations that serve different purposes, such as a combination of Terraform configuration files, VMware Cloud Templates, and ABX actions. But all integrations connect to the same GitLab server. The GitLab server can also be used for other purposes with other systems. The GitLab server can be cloud-based or on-prem (local).
After your GitLab integration is configured, we must have at least one project that interfaces to a GitLab repository as a Terraform configuration file repository:
- Create and save your GitLab integration.
- Navigate to the Projects tab.
- Add a repository to an existing vRealize Automation project by clicking +ADD PROJECT. The project must be a Terraform configurations type.
# How to add porject to Terraform repository integration
1. After the creation of Git repository integration
2. Click Project tab
Note: There are three tabs
a. Summary
b. Projects
c. History
3. click ADD PROJECT
4. Configura the project
a. Name
b. Branch # master
c. Folder
d. Type
- Terraform configurations
e. ID (pre-populated)
- Terraform is usually organized by folder. Every .tf file in a folder is related to a single configuration. Because Terraform is organized by folder, you should set up GitLab in the same way. All files related to a single Terraform configuration must appear in one folder.
- Add your repository and folder combination to your project. Each repository/folder combination is a single unit. You can have multiple repository/folder combinations in each vRealize Automation project.
- You do not have to specify a folder when you add your repository to a project. If you do not specify a folder, the content of the repository is part of the same configuration.
- Terraform can use non-Terraform files (files without the .tf extension) in the repository. For example, you can cloud-init configuration files in a repository.
Enabling Terraform in a Project
We must enable a vRealize Automation project to use cloud zone mapping for VMware cloud template Terraform resources.
# How to enable Terraform cloud zone mapping for vRA projects
1. Infrastructure tab -> Administration -> Projects
2. Select the project
3. Under Cloud Zone Mapping for Cloud Template Terraform Resources
Toggle "Allow Terraform cloud zone mapping"
Note:
i. Allow Terraform resources to deploy to cloud zones in this project.
ii. Associated cloud account credentials will be securely shared with the Terraform runtime engine.
We must enable a project to use cloud zone mapping for Terraform resources before we can deploy cloud templates that have Terraform configurations.
Verify that the cloud zone mapping for cloud template Terraform resources is enabled for the same projects that are added to the GitLab integration for Terraform configuration file management.
Configuring and Enabling the Terraform Versions
We can use multiple versions of Terraform software, depending on what the Terraform configuration files need.
# How to configure and enable Terraform versions
1. Navigate to Terraform Versions
Infrastructure tab -> Configure -> Terraform Versions
2. Click NEW TERRAFORM VERSION
# Create new Terraform version
3. Select any Terraform version, to edit/configure and enable
a. Version # Enter the version 0.12.xx
Note: Verify VMware for support Terraform version
b. Description
c. Enable
Toggle to enable/disable
d. URL # Enter the Terraform file url location
e. SHA256 Checksum # enter the sha256 checksum
4. SAVE/CANCEL
- You must enable the Terraform software that you need.
- You can add new versions of Terraform if you have the URL and the SHA256 checksum of the Terraform binary.
- Different Terraform configuration files might have been written for different versions of Terraform.
- Currently, only Terraform 0.12.xx is supported for use with vRealize Automation. However, later versions of Terraform can be added when they are added to the support list.
Preparing a Kubernetes Cluster
vRealize Automation needs a Kubernetes cluster available to run Terraform jobs:
- We must have secure access to the master node of the Kubernetes cluster.
a. If this Kubernetes cluster is managed,
i. will need the CA certificate.
ii. need a user name and password
iii. public and private certificates, or
iv. a user name and bearer token.
b. If connecting with a user name (either with a password or a bearer token),
the service user account must have cluster roles with cluster-wide privileges.
c. Connect to an external Kubernetes cluster is simpler.
To connect to an external Kubernetes cluster, the kube config file is required.
Note:
kube config
- We must have a namespace already defined in the Kubernetes cluster that vRealize Automation can use to deploy Terraform inside.
- The pod in the Kubernetes cluster is used to run Terraform open-source CLI commands.
Note:
a. The Kubernetes cluster can be a Tanzu cluster.
b. If using a Tanzu cluster, the cluster cannot be the Tanzu supervisor cluster
# How to connect a Kubernetes cluster to vRealize Automation
Navigate to Infrastructure tab -> Resources -> Kubernetes
Note:
After you connect a Kubernetes cluster under Resources > Kubernetes, even if you add it as an external cluster,
it will be treated as a managed cluster in a Terraform runtime integration.
Configuring a Terraform Runtime Integration
To create a Terraform runtime integration:
- Identify the Kubernetes cluster for the Terraform runtime integration
a. If you use a managed Kubernetes cluster, select the cluster and the namespace.
b. If this cluster is an external Kubernetes cluster, paste the kubeconfig file.
c. If this cluster is an external Kubernetes cluster, we must manually enter the namespace name.
- Specify the Docker image for the Kubernetes deployment of Terraform. You can retain or edit the default image specification.
- Configure CPU and memory limits for the Terraform pod, if required.
# How to create Terraform runtime integration
1. Navigate to Infrastructure tab -> Connections -> Integrations
2. Configure the Terraform runtime integration
a. Name # such as Test-Terraform
b. Description
c. Terraform Runtime Integration
i. Runtime type (select either)
- Managed kubernetes cluster
- External kubeconfig
ii. Kubernetes kubeconfig
# paste the kubeconfig file
d. Kubernetes namespace
3. Runtime Container Settings
a. Image # docker.io/hashicorp/terform.0.12.xx
b. CPU request (Millicores) 250
c. CPU limit (Millicores) 250
d. Memory request (MB) 512
e. Memory limit (MB) 512
Note:
Terraform runs in a small footprint. The default limits should be fine.
Creating a Cloud Template from a GitLab Terraform Repository
After integrating Terraform with vRealize Automation, you can create cloud templates from Terraform configurations.
# How to create cloud template from Terraform repository
1. Create new cloud template
2. Under NEW FROM drop down options
a. Blank canvas
b. Terraform <-- Select Terraform
c. Upload
3. In code section
resource:
terraform:
type: Cloud.Terraform.Configuration <--- Terraform configuration type
properties:
variables:
kube_ip: '${input.kube_ip}'
nginx_node_port: '${input.nginx_node_port}'
providers: []
terraformversion: 0.12.25
configurationSource:
....
We can drag a Terraform configuration component into any new or existing VMware cloud template.
Managing vRealize Automation Configurations - Using Terraform
Terraform can create and manage several vRealize Automation configurations:
1. Cloud accounts
2. Cloud zones
3. Projects
4. Blueprints (VMware Cloud Templates)
5. Deployments
6. Flavors (flavor mappings)
7. Image profiles (image mappings)
8. Storage profiles
9. Network profiles
It uses Terraform VMware Cloud Automation Services Provider.
Terraform VMware Cloud Automation Services Provider
https://registry.terraform.io/providers/vmware/vra/latest/docs
https://github.com/vmware/terraform-provider-vra
Installing the Terraform vRealize Automation provider in a Terraform server
https://blogs.vmware.com/management/2020/01/getting-started-with-vra-terraform-provider.html
http://aliihsankaya.net/vmware/installing-vra-cloud-provider-on-terraform/
https://learn.hashicorp.com/terraform/getting-started/install.html
https://garyflynn.com/technology/hashicorp/vra-and-terraform-a-new-way-to-deploy/
Configuring Terraform Configuration Files
Use the resources defined in Terraform vRealize Automation Cloud Assembly Provider to configure a standard set of Terraform configuration files.
A standard set of Terraform configuration files usually includes
1. a main.tf, and
2. a variables.tf file
3. Sometimes other files are included, such as
config.tf
terraformtf.vars
Note:
main.tf file is required
a. You can name your other configuration files the way you want.
b. All .tf files are combined into one Terraform configuration plan during execution.
But dividing different parts into different files can help you manage large, complex configurations.
Terraform Server
When you use Terraform to manage vRealize Automation, a Terraform server must be already deployed:
1. A Terraform server can run on Windows, Linux, MacOS, or in a Kubernetes pod.
2. After installing Terraform, you must install the Terraform vRealize Provider in your Terraform server.
3. Download the Terraform vRealize Automation provider
https://github.com/vmware/terraform-provider-vra/releases/latest
4. No prerequisites are required to configure vRealize Automation so that it can be managed by Terraform.
# After downloading the Terraform vRealize Automation provider, must run the command
terraform init
Verify Terraform Initialization Using the Terraform Registry
To verify the initialization, navigate to the working directory for your Terraform configuration and run terraform init. You should see a message indicating that Terraform has been successfully initialized and has installed the provider from the Terraform Registry.
The requirement of a standalone Terraform server makes managing vRealize Automation from Terraform different from using vRealize Automation to call Terraform. When vRealize Automation calls Terraform, no Terraform server is needed.
A stand-alone Terraform server is not required. You need a place to run the Terraform CLI.
Install Terraform provider for vRealize Automation
https://github.com/vmware/terraform-provider-vra/blob/main/docs/install_provider.md
Terraform vRealize Automation Provider Requirements
The Terraform vRealize Automation Provider has the following requirements
- The URL of the vRealize Automation appliance.
- The refresh token is required to access vRealize Automation.
The API Refresh token allows Terraform to establish communications with the vRealize Automation server.
Note:
A POST request is required to get the API vRA Refresh Token.
# How to configure Terraform vRA provider
provider vra {
url = var.vra_url
refresh_token = var.vra_refresh_token
insecure = true
}
variable "vra_url" {
description = "URL for vRA"
default = "https://test-vra-01.test.lab"
}
variable "vra_refresh_token" {
description = "vRA Refresh token"
default = "<vra-fresh-token>" # Uinsg POT request to obtain the API vRA refresh token
}
API POST Request for vRA refresh token
Run API POST request call using Google Postman
POST https://<vra-server>/csp/gateway/am/idp/auth/login?access_token
Applying a Terraform Configuration to vRealize Automation
After writing your configuration files and downloading and installing your vRealize Automation provider, you can run the configuration with the terraform apply command.
1. You must initialize Terraform with terraform init before you run terraform apply.
2. The terraform apply command uses all the files in the current folder as part of the configuration that will be applied.
Integration with Kubernetes
Modern applications running as micro-services are more suited to run on the Kubernetes platform. vRealize Automation supports integration with several Kubernetes platforms to automate the deployment of Kubernetes components.
Using vRealize Automation, administrators can monitor and obtain an overview of multiple Kubernetes clusters at once. Enterprise licensing is required for Kubernetes integration. The following Kubernetes integration options are available:
1. vSphere with Tanzu
2. VMware Enterprise PKS
# formerly call VMware PKS
# new name - Tanzu Kubernetes Grid Integrated Edition
3. External Kubernetes
4. Red Hat OpenShift
vRealize Automation integration with Kubernetes
- vRealize Automation supports integration with multiple Kubernetes platform
- vRealize Automation can be integrated with vSphere with Tanzu for requesting on-demand supervisor namespaces
- A vRealize Automation user can log in to the on-demand supervisor namespace and deploy the Tanzu Kubernetes cluster manually
- The vRealize Automation users can use the Tanzu Kubernetes cluster as they use a vanilla Kubernetes cluster
- Vanilla Kubernetes clusters can be added to vRealize Automation to create and manage namespaces
- VMware Enterprise PKS must be integrated to deploy an on-demand Kubernetes cluster by using a cloud template.
A cluster that is enabled with vSphere with Tanzu is called a supervisor cluster. The supervisor cluster runs on an SDDC layer that includes the following elements:
- ESXi for compute
- NSX-T Data Center for networking
- vSAN or other shared storage solution as the shared storage for vSphere pods, Tanzu Kubernetes Clusters, and VMs that run in the supervisor cluster
After a supervisor cluster is created, we can create namespaces in the supervisor cluster that are called Supervisor Namespaces.
DevOps engineers can run workloads that include containers. These containers run in vSphere pods. A vSphere pod is equivalent to a Kubernetes pod.
Note:
1. A vSphere pod is a VM with a small footprint that runs one or more Linux containers.
2. The vSphere pods are deployed directly on the ESXi hosts.
VMware Tanzu Kubernetes Grid Integrated Edition
https://docs.vmware.com/en/VMware-Tanzu-Kubernetes-Grid-Integrated-Edition/index.html
VMware Tanzu Kubernetes Grid Integrated Edition (formerly known as VMware Enterprise PKS) is a Kubernetes-based container solution with advanced networking, a private container registry, and life cycle management.



Tanzu Kubernetes Grid Integrated Edition (TKGI) simplifies the deployment and operation of Kubernetes clusters so you can run and manage containers at scale on private and public clouds. With TKGI, you can provision, operate, and manage Kubernetes clusters using the TKGI Control Plane.
vSphere with Tanzu
https://www.vmware.com/au/products/vsphere/vsphere-with-tanzu.html
vSphere with Tanzu transforms vSphere into a native Kubernetes platform.

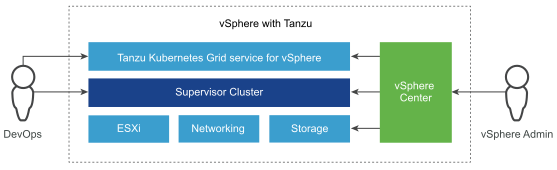
Supervisor Cluster overview

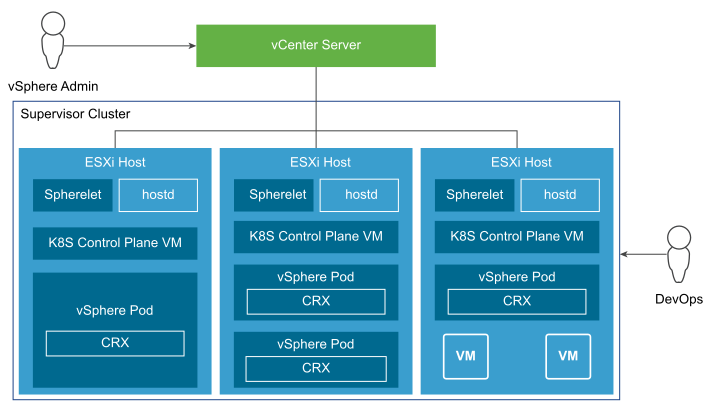
A cluster that is enabled for vSphere with Tanzu is called a Supervisor Cluster. It runs on top of an SDDC layer that consists of ESXi for compute, NSX-T Data Center or vSphere networking, and vSAN or another shared storage solution. Shared storage is used for persistent volumes for vSphere Pods, VMs running inside the Supervisor Cluster, and pods in a Tanzu Kubernetes cluster. After a Supervisor Cluster is created, as a vSphere administrator you can create namespaces within the Supervisor Cluster that are called vSphere Namespaces. As a DevOps engineer, you can run workloads consisting of containers running inside vSphere Pods and create Tanzu Kubernetes clusters.
vSphere Namespace

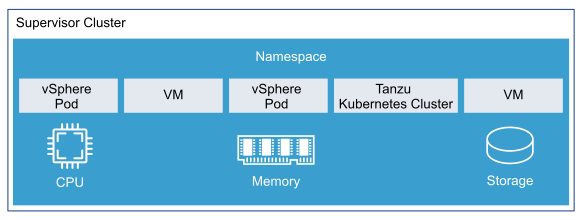
A vSphere Namespace sets the resource boundaries where vSphere Pods and Tanzu Kubernetes clusters created by using the Tanzu Kubernetes Grid Service can run. When initially created, the namespace has unlimited resources within the Supervisor Cluster. As a vSphere administrator, you can set limits for CPU, memory, storage, as well as the number of Kubernetes objects that can run within the namespace. A resource pool is created per each namespace in vSphere. Storage limitations are represented as storage quotas in Kubernetes.
Tanzu Kubernetes Clusters
A Tanzu Kubernetes cluster is a full distribution of the open-source Kubernetes software that is packaged, signed, and supported by VMware. In the context of vSphere with Tanzu, you can use the Tanzu Kubernetes Grid Service to provision Tanzu Kubernetes clusters on the Supervisor Cluster. You can invoke the Tanzu Kubernetes Grid Service API declaratively by using kubectl and a YAML definition.
A Tanzu Kubernetes cluster resides in a vSphere Namespace. You can deploy workloads and services to Tanzu Kubernetes clusters the same way and by using the same tools as you would with standard Kubernetes clusters.

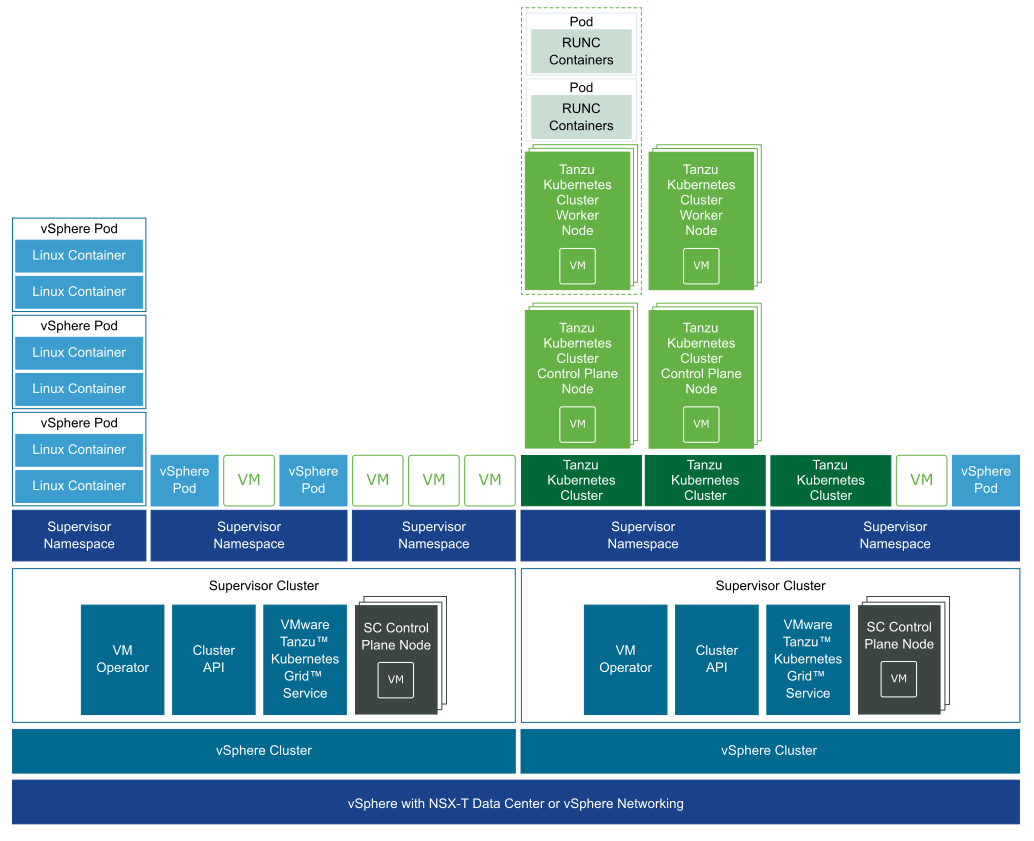
vSphere with Tanzu: Virtual Machines
To run container-based workloads natively on vSphere, we enable Workload Management:
- A three-node supervisor cluster is deployed.
- Manually create a supervisor namespace on the supervisor cluster.
- (Optional) Deploy a Tanzu Kubernetes cluster.
The following objects are visible in the Hosts and Clusters view in vSphere client:
- Supervisor (vSphere) namespace
- vSphere pods
- Tanzu Kubernetes cluster
- Harbor registry
- Supervisor cluster
# Explorer vSphere with Tanzu Cluster (K8s cluster)
1. In vSphere client, navigate to K8s cluster and expand the cluster
2. Expand Namespaces
# all K8s namespaces, Harbar registry and 3 node supervisor cluster nodes are under "Namespaces" object
3. Navigate to and expand namespaces(x) # where x is the number of the namespace
a. There are pod VMs running under the individual namespace
4. Navigate to and expand 'vmware-system-registry-xxxx'
# Harbor registry pods running under this object
a. There are 'harbor-xxxx-habor-xxx' # There are individual harbor pod VMs
5. # Three node supervisor cluster objects
SupervisorControlPlaneVM (1)
SupervisorControlPlaneVM (2)
SupervisorControlPlaneVM (3)
You can select between creating the supervisor cluster with the vSphere networking stack or with NSX-T Data Center as the networking solution.
You must need a valid Tanzu Edition license to enable Workload Management
Supervisor namespace
The supervisor namespace is also called as vSphere namespace.
You create a supervisor namespace on a supervisor cluster and configure it with resource quota, storage policy, user permissions,
and associate it with a Content Library for fetching the latest Tanzu Kubernetes cluster files.
vSphere pod
A vSphere pod is a VM with a small footprint that runs one or more Linux containers.
The vSphere pods are running directly on the ESXi hosts, managed by the supervisor cluster.
Tanzu Kubernetes cluster
You log in to the supervisor cluster namespace and use the content library files to deploy a Tanzu Kubernetes cluster.
The Tanzu Kubernetes cluster details can be provided to a developer.
The developer can manage the Tanzu Kubernetes cluster as a normal Kubernetes cluster using the kubectl commands.
Harbor registry
You can use images that are stored in the Harbor registry to deploy vSphere pods in namespaces on the supervisor cluster.
Supervisor cluster
A Kubernetes management cluster where you run vSphere pods and provision Tanzu Kubernetes clusters.
vSphere with Tanzu - Supervisor Cluster
The supervisor cluster includes a set of control plane VMs that provide API access to the supervisor cluster. The control plane VM serves as an endpoint for Kubernetes users to manage their namespaces using the familiar kubectl command-line interface.
The three control plane VMs are load balanced because each load balancer has its own IP address. Additionally, a floating IP address is assigned to one of the VMs.
An additional process called Spherelet is created on each host. This kubelet is ported natively to ESXi and allows the ESXi host to become part of the Kubernetes cluster.
The supervisor cluster provides the management layer on which Tanzu Kubernetes clusters are built. Tanzu Kubernetes Grid Service (TKGS) is a custom controller manager with a set of controllers that is part of the supervisor cluster. Tanzu Kubernetes Grid Service provisions Tanzu Kubernetes clusters.
vSphere with Tanzu - Tanzu Kubernetes Cluster
Tanzu Kubernetes clusters are built on the supervisor cluster, which is a Kubernetes cluster that runs in a supervisor cluster namespace.
- Running a Tanzu Kubernetes cluster can be compared to running traditional Kubernetes clusters by using VMs and a container host OS.
- Tanzu Kubernetes Grid Service that runs in the supervisor control VMs automates the deployment of the Tanzu Kubernetes cluster.
- A Tanzu Kubernetes cluster object can consist only
a. Tanzue Kubernetes cluster control plane VMs # three node cluster (3 VMs)
b. worker VMs
Note:
1. Sphere pods cannot be deployed into a Tanzu Kubernetes Cluster
2. vSphere administrator manage Supervisor cluster
3. Developers use Tanzu Kubernetes cluster
a. Controller Plane VMs
b. Worker VMs
Note: They could also create T8s namespace
vSphere with Tanzu - Integration
After enabling vSphere with Tanzu, the supervisor cluster can be integrated with vRealize Automation.
# How to integrate vSphere with Tanzu
1. In vSphere client, navigate to cluster and enable vSphere with Tanzu
2. Access vRealize Automation console -> Cloud Assembly
3. Click Infrastructure tab
4. Navigate to Resources -> Kubernetes
5. Click the Supervisor Clusters tab
6. Click ADD SUPERVISOR CLUSTER
a. Account # Cloud account, such as TEST-vCenter-01
b. Supervisor cluster # Select the supervisor cluster, such as Test-Management
vSphere cloud accounts with Workload Management enabled can be used as managed Kubernetes providers. These accounts also offer at least one supervisor cluster and namespace.
Managing Supervisor Namespaces
After integrating the supervisor cluster with vRealize Automation, we can perform the following tasks
- Manage existing supervisor namespaces
- Create supervisor namespaces
# How to manage supervisor namespce
1. Access vRealize Automation console -> Cloud Assembly
2. Click Infrastructure tab
3. Navigate to Resources -> Kubernetes
4. Click the Supervisor Clusters tab
5. Select the required supervisor cluster, and open the supervisor cluster window
6. Select Supervisor Namespace tab
a. Summary
b. Supervisor Namespaces <-- Select
7. Click New Supervisor Namespace # create new supervisor namespace
a. Name # Name of new supervisor namespace
b. Description
c. Project # Select the project for the new supervisor namespace
d. click CREATE
8. Click Add To Project
# Select existing supervisor namespace and add to project
You can add an existing supervisor namespace to vRealize Automation to a project.
All the project users are provided edit access to the existing namespace.
The new supervisor namespace created from vRealize Automation can be used to deploy vSphere pods or Tanzu Kubernetes clusters.
Kubernetes Zone
We must create a Kubernetes zone with a supervisor cluster for creating namespaces on demand:
# How to create Kubernets zone
1. Login to vRealize Automation console
2. Click the Infrastructure tab.
3. Navigate to Configure > Kubernetes Zones.
4. Click +NEW KUBERNETES ZONE.
Note:
A kubernetes zone offers a set of compute resources that can be used for provisioning of clusters and namespaces
5. Specify the details on the Summary tab
a. Account # select the vCenter account
b. Name # enter the kubernetes zone name
c. Description
d. Capabilities
i. Capability tags
e. SAVE
6. Select Provisioning tab
a. Select the vSphere cluster that we have enabled vSphere with Tanzu
7. Edit a vRealize Automation project, and click the Kubernetes Provisioning tab to
associate the Kubernetes zone with the project
Cloud Template: On-Demand Namespaces
We create a cloud template to deploy supervisor namespaces on demand:
- Drag the Kubernetes Supervisor Namespace to the design canvas.
- Configure Input in the YAML section.
The cloud template can be made available in the Service Broker catalog.
At the time of creating the cloud template, we must select the project with the Kubernetes zone. Configure input for the users to enter their namespace when requested. We can version the cloud template and release it to Service Broker. The catalog item can be made available for the business users.
Deploying the Tanzu Kubernetes Cluster
The steps to log in to the on-demand supervisor namespace can be accessed from the deployment. The Tanzu Kubernetes cluster can also be deployed on the requested on-demand namespace.
Currently, vRealize Automation does not support deploying Tanzu Kubernetes clusters. The user must log in to the on-demand supervisor namespace and use kubectl to deploy the Tanzu Kubernetes cluster manually.
# How to deploy the Tanzu kubernetes cluster
1. In design canvas, drag the on-demand supervisor namespace to the canvas
2. Select the on-demand supervisor namespace object/component, and click Properties section
a. General
i. Resource name <Test-ns-01>
ii Supervisor cluster <supervisor cluster name>
iii. Status # Ready
iv. Address # https://<ip-address>
Note:
- click the address link, to login
- Download the modified kubectl
- Run "kubectl vsphere login --vsphere-server=<ip-address>"
# To deploy a Tanzu Kubernetes cluster as a vRealize Automation user
1. Request to deploy on-demand supervisor namespace
2. Use the link from the deployment to download the modified kubectl
3. Use kubectl to log in to the supervisor cluster
kubectl vsphere login --vsphere-username test1@vclass.local --server=<ip-address>
4. Log in to the on-demand supervisor namespace
kubectl config use-context test1
5. Deploy the Tanzu Kubernetes cluster
kubectl apply -f c:\Download\Tanzu\deploy-tkc.yaml
Note: The OVA file to deploy the cluster must be uploaded to the content library.
a. Users can use kubectl to log in to the Tanzu Kubernetes cluster.
b. Users can deploy pods and services like they might on a vanilla Kubernetes cluster.
Integrating VMware Enterprise PKS (VMware Tanzu Kubernetes Grid Integrated Edition)
VMware Enterprise PKS simplifies the deployment and management of Kubernetes clusters so that you can run and manage containers at scale on private and public clouds.
# How to integrate VMware Enterprise PKS
1. Navigate to the Infrastructure tab
2. Click Connections > Integrations
3. Click + ADD INTEGRATION
4. Select VMware Enterprise PKS
a. Name # Test-PKS
b. Description
c. PKS Endpoint Credentials
i. IP address / FQDN # https://<fqdn>:8443
Toggle "Configure ports manually"
ii. Username
iii. Password
iv. CA certificate # copy and paste the CA certificate
Click VALIDATE
d. Capabilities
Capability tags # enter the capability tags
Click ADD
VMware Enterprise PKS is built in with critical production capabilities such as high availability, autoscaling, health checks, and self-healing and rolling upgrades for Kubernetes clusters. It provides the latest stable Kubernetes release, so that the latest features and tools are available to the developers.
VMware Enterprise PKS also integrates with NSX-T Data Center for advanced container networking including micro-segmentation, ingress controller, load balancing, and security policy. Through an integrated private registry, VMware Enterprise PKS secures a container image through features such as vulnerability scanning, image signing, and auditing.
VMware Enterprise PKS - Kubernetes Zone
Kubernetes zones enable cloud administrators to define policy-based placement of Kubernetes clusters and namespaces.
# How to create a Kubernetes zone
1. Navigate to the Infrastructure tab
2. Click Configure > Kubernetes Zones
3. Click + NEW Kubernetes Zone
4. On New Kubernetes Zone window, there are three tabs
a. Summary
b. On-demand
c. Clusters
5. Click Summary tab
a. Account # Select the compute cluster has been enabled for Kubernetes
b. Name # enter the name of the k8s zone
c. Description
d. Capabilities
# Capability tags are effectively applied to all compute resources in this kubernetes zone, but only in the context of this zone
- Capability tags # enter capability tags
SAVE
On the On-demand tab, select one or more PKS plans and assign priorities to them. You can define the number of workers, masters, available CPU, memory, and other configuration settings in a PKS plan.
You must associate the Kubernetes zone with a project before creating a cloud template.
VMware Enterprise PKS - Cloud Template
We create a cloud template to deploy an on-demand Kubernetes cluster and namespace. To deploy on-demand Kubernetes clusters, we must integrate VMware Enterprise PKS.
# How to create VMware Enterprise PKS cloud template
1. On new cloud template design canvas
There are following tabs
a. Deployments
b. Design <----------- Design canvas
c. Infrastructure
d. Extensibility
e. Tenant Management
f. Marketplace
2. Select Design tab
3. On the left components, expand Kubernetes, and select the following component
a. K8S Cluster
b. K8S Namespace
c. Supervisor Namespace
Only two Kubernetes components are available to use when integrated with VMware Enterprise PKS
- K8S Cluster: Deploys an on-demand Kubernetes cluster in the Kubernetes zone associated with the project.
- K8S Namespace: Creates an on-demand namespace to be used by the Kubernetes clusters.
Kubernetes Cluster Options
The option that we select to integrate vRealize Automation with Kubernetes depends on the platform and use case:
1. Deploy: A PKS cloud account must be created
# Used to deploy on-demand Kubernetes clusters
2. Add Existing: A PKS cloud account must be created
# Used to import existing Kubernetes clusters deployed by PKS
3. Add External: Connectivity to vanilla Kubernetes cluster
# Used to import an existing vanilla Kubernetes cluster
# How to configure Kubernetes cluster options
1. In vRealize Automation Cloud Assembly
2. Select Infrastructure tab
3. On left expand Resources -> Kubernetes
# Under Resources, there are different resources available
a. Compute
b. Networks
c. Security
d. Storage
e. Machines
f. Volumes
g. Kubernetes
4. On the Kubernetes window
# there are tabs - Clusters, Namespaces, Supervisor Clusters, Supervisor Namespaces
a. Clusters tab
# A list of all clusters that you have deployed. added from existing endpoints, or connected to
i. DEPLOY
ii. ADD Existing
iii. ADD External <------ Select to add external vanilla k8s cluster
b. Namespaces tab
# A list of all namespaces that you have created or added from existing clusters
i. NEW Namespace
ii. ADD Namespace
c. Supervisor Clusters tab
# A list of all supervisor clusters you have started managing
i. ADD Supervisor Cluster
d. Supervisor Namespaces tab
# A list of all supervisor namespaces you have started managing
i. NEW Supervisor Namespace
ii. ADD Supervisor Namespace
Note:
Currently, PKS only supports deploying Kubernetes clusters on demand.
Integrating Vanilla Kubernetes
An existing vanilla Kubernetes cluster can be imported into vRealize Automation. You cannot deploy a new vanilla Kubernetes cluster from vRealize Automation.
After a Vanilla Kubernetes cluster is imported into vRealize Automation, you can perform the following tasks:
- Create a namespace
- Add an existing namespace
You can create a Kubernetes zone and associate it with a project. Cloud templates can also be created to request on-demand namespaces on the external Kubernetes cluster
How to add an existing Kubernetes cluster
1. In vRealize Automation Cloud Assembly
2. Select Infrastructure tab
3. On left expand Resources -> Kubernetes
4. Select ADD EXTERNAL
5. On Add External Cluster window
a. Name # enter the name
b. Description
c. Sharing # Toggle to select on the following options
i. Global (shareable via kubernetes zones or namespaces)
ii. Project (access limited to a single project)
d. Cluster Credentials
i. Address # https://<k8s-fqdn>
ii. CA certificate # paste in the certificate
iii. Credentials type
- Bearer token # select from the drop down list
iv. Bearer token # paste in the bearer token
e. Click VALIDATE
ADD
Integrating Red Hat OpenShift
Red Hat OpenShift is an enterprise Kubernetes application platform built on the Red Hat Enterprise Linux (RHEL) operating system.
You can create a Kubernetes zone and associate it with a project. Cloud templates can also be created to request on-demand namespaces on the OpenShift Kubernetes cluster.
How to add an existing Red Hat OpenShift integration
1. In vRealize Automation Cloud Assembly
2. Navigate to the Infrastructure tab
3. Click Connections > Integrations
4. Click + ADD INTEGRATION
5. Select Red Hat OpenShift
6. On the New Integration window
a. Name # enter the name
b. Description
c. OpenShift endpoint Credentials
i. Address # https://<openshift-fqdn>:8443
ii. Credentials type
- Bearer token # select from the drop down list
iv. Bearer token # paste in the bearer token
d. CA certificate # paste the certificate
Click VALIDATE
e. Capabilities
- Capabilities tags # enter capability tags
ADD
SaltStack Config
vRealize Automation SaltStack Config is a configuration management tool. SaltStack Config can manage the configurations of the deployed systems in your environment. You apply Salt states to your managed system to get them in the required configuration. SaltStack Config uses beacons and reactors to monitor different activities on your managed systems and respond to them.
SaltStack is a configuration management system that enables you to define the applications, files, and other settings that should be in place on target systems. These target systems are evaluated against their respective defined configuration, and changes are made as needed.
You can use SaltStack Config for data-driven orchestration, remote execution for any infrastructure, configuration management for any app stack, and so on.
Salt Master and Minion
SaltStack Config has the following classes of systems
- Salt master: This central management system runs the Salt master service. This service is used to send commands and configurations to the Salt minions.
- Salt minion: This managed system is controlled by the Salt master. It runs the Salt minion service, which receives commands and configuration from the Salt master and runs them.
Salt uses a server-agent communication model. The server component is the Salt master, and the agent is the Salt minion. The Salt master is responsible for sending commands to Salt minions. The Salt master also aggregates and displays the results of those commands which are received from the Salt minions. A single Salt master can manage thousands of systems. The Salt minion can also run agentless using salt-ssh.

SaltStack Management Interface
SaltStack management interface has the following configuration items on the left pane
- root
- Dashboard
- Reports
- Minions
- Minion Keys
- Activity
- Config
- Settings
- Administration
- Logout
SaltStack Config features include
- A web-based user interface
- Role-based access control
- Multimaster support
- Central job and event cache
- Scheduling UI
- LDAP and Active Directory integration
- Reporting
- An enterprise API (eAPI)
Communication Between Salt Master and Salt Minion
Salt master communicates with Salt minions by using a publish-subscribe pattern. The following ports are used
- Port 4505: All Salt minions establish a persistent connection to this publisher port where they listen for messages. Salt minions execute the message published if they are the targeted minions.
- Port 4506: Salt minions use this port as needed to send jobs results to the Salt master, and to securely request files and minion-specific data values from the Salt maste
The communication takes place as follows
- A user runs a Salt command on defined target Salt minions.
- Salt master takes this defined command and publishes it on port 4505.
- Communication from the Salt master is a lightweight set of instructions that basically say: If you are a Salt minion with these properties, run this command with these arguments. All Salt minions receive commands simultaneously.
- Salt minions determine if they match the target properties when the command is received. If the Salt minion matches the target properties, it runs the command. Otherwise, it ignores the command.
- The results from the targeted Salt minions are returned to the Salt master on port 4506.
When you run a job in SaltStack Config user interface, this job passes through the SaltStack Config RAAS API toward the respective Salt master.
SaltStack Config Installation
You can install SaltStack Config from vRealize Suite Lifecycle Manager.
# How to install SaltStack Config
1. Login to vRealize Suite Lifecycle Manager
2. Navigate to Lifecycle Operations > Environments
3. Select vRealize Automation environmentthe, and click "..." then select Add Product
4. On vRealize Automation SaltStack Config window
a. Installation type
Select New Install
b. Version # select from the drop down list
c. Deployment Type
i. Standard # select the requird version
# Minimum resource requirement for SaltStack Config appliance
8 CPU
16 GB Memory
40 GB Hard disk
Note:
To Install SaltStack Config, vRealize Automation should be installed in the environment
SaltStack Config installation requires enabling multitenancy in vRealize Suite Lifecycle Manager because SaltStack Config is integrated with a vRealize Automation tenant.
SaltStack Config Integration in vRealize Automation
After installing SaltStack Config, a new SaltStack Config service appears under MY Services in the vRealize Automation Service Console of the tenant. After clicking the SaltStack Config service, you can log in to SaltStack Config.
An integration is also created in Cloud Assembly with SaltStack Config, which appears under Connections > Integrations.
Salt Master Keys
The SaltStack Config appliance is also a Salt master and a Salt minion. The master key is automatically accepted after the installation. To view the accepted master keys, navigate to Administration > Master Keys > Accepted.
When installing multiple Salt Master in the same SaltStack Config, after a new Salt master is connected to SaltStack Config, you can accept its key from Administration > Master Keys > Pending. Select the key and click ACCEPT KEY.
Salt Minion Installation
You need to install Salt minion on your managed systems. You can use cloudConfig in vRealize Automation to run the following commands on Linux VMware Cloud Templates deployments
# Download the installation script
curl -L https://bootstrap.saltstack.com -o install_salt.sh
# Run the script to install Salt minion and specify with Salt master IP address
sudo sh install_salt.sh -A <Salt-Master-IP-Address>
# Install Salt Minion as part of cloud template configuration
In YAML code, add the following code
resources:
Cloud_Machine_1:
type: Cloud.Machine
properties:
image: VMW-Ubuntu-Salt
flavor: VMW-Small
cloudConfig:
runcmd:
- curl -L https://bootstrap.saltstack.com -o install_salt.sh
- sudo sh install_salt.sh -A <Salt-Master-IP-Address>
Note: Windows Salt Minion installation
https://docs.saltproject.io/en/latest/topics/installation/windows.html
SaltStack Config manages these deployments
Salt Config manages a minion with the minion ID saltmaster. SaltStack Config runs as Salt master and Salt minion at the same time.
Accepting Minion Keys
When the Salt minion starts for the first time, it sends its key to the Salt master. Salt master does not manage Salt minion until the Salt minion’s key is accepted.
# How to accept Salt minion key
1. In SaltConfig management interface
2. Navigate to Minion Keys
a. Accepted
b. Pending <---- select Pending
i. Accepted Key
ii. Rejected Key
iii. Delete Key
c. Rejected
d. Denied
3. select the key, and click ACCEPT KEY
Command Structure
Salt commands have a well-defined structure with the following main components
- Target specification
- Module and function to call
- Function arguments
To run a command, navigate to Minions and click RUN COMMAND
# Run Salt command
In Run Command window, specify the paramters
1. Command # select on the following options
a. salt
b. salt-run
2. Targets
Select or enter the salt minion target, such as "Test Web Servers"
3. Function
select or enter the function, such as
pkg.install # install package
4. Arguments
Enter the argument, such as nginx
5. Click ADD ARGUMENT to add more argument if required
6. Click RUN COMMAND
After installing SaltStack Config and accepting your Salt minion keys, you can run Salt commands.
All responses from the command runs are returned by the Salt minions so that you can identify command failures and successes. The following command types are available:
- salt: Runs one of a subset of available modules on the target Salt minions.
- salt-run: Runs one of a subset of available modules directly on the Salt master.
Targeting
You use targeting to select your target Salt minions when running commands, apply configurations, and performing tasks in SaltStack Config that involve a Salt minion.
# How to create a target
1. In SaltConfig management console
2. navigate to Minions
3. On Targets window
a. All Minions
b. Centos
c. MacOS
d. Redhat
e. SUSE
f. Salt Master
g. Ubuntu
h. Windows
i. Windows Servers
Select All Machines
3. On right window
a. Run Job
b. Run Command
c. CREATE TARGET
click + CREATE TARGET
4. Then you define your targeting criteria and click SAVE
a. Name # define name of target
b. All Masters # toggle to enable or disable the selection
c. Glob (or select one of the option)
Type the match criteria
d. Click ADD MATCH CRITERIA # to add more match criteria
5. Click SAVE
The following ways of targeting criteria are available
- Grains: Static information that SaltStack collects from the Salt minions
- Glob: Allows you match one or more Salt minion IDs by using a wildcard matching
- List: Defines a list of Salt minion IDs
- Compound: Allows for many matchers to determine the target
Compound matches https://docs.saltproject.io/en/latest/topics/targeting/compound.html
The simplest way to target is using the Salt minion ID. By default, the minion ID is by default the minion host name. The wildcard matching in Glob targeting can be
1. Zero or more characters (*)
2. Single character match (?)
3. Range, for example, [1-5]
4. List, for example, [1,2,4]
Pre-defined targets are available in SaltStack Config. These targets match the target by their operating systems.
Salt Minion Grains
https://docs.saltproject.io/en/latest/topics/grains/index.html
Grains are static information which SaltStack collects from the Salt minions. Grains are composed of system properties, such as the operating system, domain name, IP address, kernel, OS type, memory, and so on.
# How to view the grains for a specific Salt minion
1. Navigate to Minions
2. Click the Salt minion
3. All the grains collected for this Salt minion appear on the Grains tab
Grains target Salt minions. You can add your grains to a Salt minion. These grains are called custom grains.
Salt Modules
https://docs.saltproject.io/en/latest/ref/index.html
A Salt module is a group of functions that manage an application (MySQL, Docker), a system component (disk, file), or interact with an external system. When you run a Salt command, you call a function in a module that performs a specific task.
# Common modules
1. pkg: Package management
2. service: Managing services/daemons
3. cp: File management
4. user and group: Managing users and groups
5. network: Network management
6. cmd: Run a command
Modules are named in the format salt.subsystem.module
Salt States
SaltStack configuration management enables you to create a reusable configuration template that describes the elements required to put a system component or application into a known configuration. This configuration template is the Salt state. You can create and save state files in the File Server, which is under the Config tab. The main use of the Salt file server is to present files for use in the Salt state system.
# Use SaltStack file server
1. In SaltStack Config management UI
2. Navigate to File Server
3. You create folder structure
a. base
i. _beacons
ii. presence
iii. reactors
# create your required folder structure, such as
iv. nginx
init.sls # Salt state file, wirtten in YAML format, defines the nginx state
install_nginx_server: # ID: string that describes the state
pkg.installed: # module.function
-name: nginx # arguments
SAVE
Note:
- calls the function installed in the pkg module to install nginx on the target minions.
b. sse
Note:
1. Salt states are written in YAML format.
2. A state file is a file with an SLS extension that contains one or more state declarations.
3. Commands in state files are run by default from top to bottom.
Salt uses the term state because the configuration management system defines the state for a system. Salt states can restart services, copy entire directories, use variables, and so on.
You can use the Salt file server for general file transfer from the Salt master to the Salt minions.
Pillars
https://docs.saltproject.io/en/latest/topics/tutorials/pillar.html
Sensitive data specific to each Salt minion can be stored in pillars. Information transferred through a pillar is presented only to the Salt minions that are targeted.
Pillar data is compiled using targeting to determine the data that is sent to each minion.
Jobs
Jobs run a salt command or apply a salt state to the target Salt minions.
# How to create job
1. In SaltStack management UI
2. Navigate to Config > Jobs
3. click CREATE JOB
The following items are defined when creating a job
a. Name
b. Description
b. Command
i. salt # run at salt minion
ii. salt-run # run at salt master
c. Target
Select the target from the drop down option
d. Function
Select from the drop down, or enter <function-name>.sls
e. Environments
i. base # select from the drop down list
e. States
e. Argument
click ADD ARGUMENT to add more argument(s)
SAVE
Beacons
Beacons enable the Salt minion to monitor and raise events for processes that are not Salt-related. The beacon system allows the Salt minion to hook into system processes and continually monitor these processes. When the monitored activity occurs in a system process, an event is sent on the Salt event bus.
# Salt beacons can monitor many system activities including
1. File system changes
2. Service status
3. Shell activity, such as user login
4. Network and disk usage
Beacons configurations are enabled by placing a beacons: top-level block in the /etc/salt/minion file
or any file in /etc/salt/minion.d/ such as /etc/salt/minion.d/beacons.conf
# Example
beacons:
inotify:
- files:
/var/www/testsite/index.html:
mask:
- modify
- disable_during_state_run: True
Reactors
Reactors enable the Salt master to trigger actions in response to any event. Reactors watch the event bus for event tags that match a given pattern and run one or more commands in response.
reactor:
- 'salt/beacon/*/inotify//var/www/testsite/index.html': <---- event tag
- salt://reactors/update.sls
Note:
1. When event tag matches "salt/beacon/*/inotify//var/www/testsite/index.html", then
2. run the salt state file
update.sls
# Reactor configurations are enabled by placing a
reactor:
at the top-level block in /etc/salt/master file or
defining it in a separate reactor.conf file in the /etc/salt/master.d/ directory.
Reacting to Events with Beacons and Reactors
Beacons and reactors work together to provide orchestration:
- Beacons keep monitoring activities. When the monitored activity occurs, they trigger events.
- The triggered events fire the respective reactors.
- Reactors responds to the triggered events by sending commands and states for the Salt minions to apply.
Troubleshooting and Integration with vRealize Suite
vRealize Automation has many components. You need comprehensive knowledge of CLI functions and logs to monitor and troubleshoot different vRealize Automation components. Integration with vRealize Suite products provides more features and capabilities.
Overview of CLI
The CLI is a text-based function of vRealize Automation. The CLI includes Kubernetes and vRealize Automation commands. Several command sets can be used:
- vracli: A custom-built administration and troubleshooting command set for the vRealize Automation appliance infrastructure. It is used for initial configuration, cluster management, database, certificates, log bundle generation, and others.
- kubectl: A command set used to manage Kubernetes services, pods, and container-level functions in the environment. kubectl is the primary command set used after installation.
vracli Commands
vracli has different commands to monitor, configure, and gather information about the vRealize Automation infrastructure.
# To access the help menu, enter the
vracli -h or
vracli
Note:
All commands can be autocompleted by pressing Tab.
--------------------------------------------------------------------
Command Usage
--------------------------------------------------------------------
vracli status deploy Confirms that the deployment is successful
--------------------------------------------------------------------
vracli status Gives an overview of the entire vRealize Automation cluster infrastructure and database
--------------------------------------------------------------------
vracli service status Shows detailed information about each service and its memory/disk usage
--------------------------------------------------------------------
vracli vidm Displays or changes the VMware Identity Manager configuration.
vracli log-bundle Creates a log bundle in the current working director
--------------------------------------------------------------------
kubectl Commands
kubectl is the main command set for managing Kubernetes services and pods.
# To access the help menu, enter the
kubectl -h or
kubectl
--------------------------------------------------------------------
Command Usage
--------------------------------------------------------------------
kubectl get namespaces Shows all the available namespaces
--------------------------------------------------------------------
kubectl get pods
-n {namespace} Gives information about the pods in a given namespace
--------------------------------------------------------------------
kubectl get services
-n {namespace} Gives information about the services in a given namespace
--------------------------------------------------------------------
kubectl describe Gives a detailed breakdown of startup parameters and processes of an individual pod
pod {pod name}
-n {namespace}
--------------------------------------------------------------------
kubectl logs Checks the logs for a specific service pod in a given namespace
{pod name}
-n {namespace}
--------------------------------------------------------------------
Note: You can replace -n {namespace} with -A to view items in all namespaces
Restarting a Service
If a particular service fails, restarting this service can be a fix.
# Restarting a service is a destroy and autoredeploy of this service by using command
kubectl delete pods -n {namespace} {pod name}
Note:
The kubectl delete command does not require a full system restart and can fix most services.
# Query running services pods and their status in the prelude namespace
kubectl get pods -n prelude -w
Note: Adding -w to the end of the command follows changes in the environment similar to a tailing log.
# Query about service dependencies
kubectl describe {pod name} -n {namespace}
deploy.sh Script
The deploy.sh script retrieves all images from the helm registry and redeploys the vRealize Automation services based on the configuration files.
# To rebuild all services, run scripts
1. Run onlyClean first
/opt/scripts/deploy.sh --onlyClean
2. After successfully clean, then run deploy
/opt/scripts/deploy.sh # force all the services to rebuild
The information in the Postgres database remains intact, and service pods are reconfigured.
Upgrade or patching process
- Run the /opt/scripts/deploy.sh --onlyClean script first
- After vRA has stopped the services cleanly, then
- Take a backup or snapshot of the vRA appliance
- Run /opt/scripts/deploy.sh
- Check operation finishes and ensure services healthy and data integrity
# How to shutdown vRA properly to preserve data integrity
1. Shutdown vRA services
/opt/scripts/svc-stop.sh
2. Sleep 120 # wait for 120 seconds
3. /opt/scripts/deploy.sh --onlyClean # run command to stop all services
4. Shutdown vRA appliance
# How to properly start vRA appliance
1. Power on vRA appliance
2. /opt/scripts/deploy.sh # run command to restore the services
Log Bundle Collection
You can collect the complete vRealize Automation environment logs as one bundle.
# How to create a log bundle
1. use SSH to connect to the vRealize Automation appliance
2. and run the command
vracli log-bundle
Note:
In a clustered deployment,
running the vracli log-bundle command on only one node pulls logs from all nodes in the environment.
Log Bundle Structure
The log bundle is a timestamped TAR file.
1. The name of the bundle
log-bundle-<date>T<time>.tar
2. The log bundle consists of the following content:
a. Environment file:
The environment file contains the output of various Kubernetes commands.
It supplies information about current resource usage per node and per pod.
It also contains cluster information and description of all available Kubernetes entities.
b. Host logs and configuration:
The configuration of each host (for example, its /etc directory) and
the host-specific logs (for example, journald) are collected in one directory for each cluster node or host.
The name of the directory matches the hostname of the node.
c. Services logs:
Logs of the running Kubernetes services are available in
<hostname>/services-logs/<namespace>/<app-name>/container-name>.log
An example filename is host-01/services-logs/prelude/vco-app/vco-server-app.log
Important Logs
The table includes key logs and their location in the log bundle for troubleshooting the appliance in addition to the services logs.
Log Location in Bundle Description
--------------------------------------------------------------------------------------------
/services-logs/ingress/traefik/ingress-ctl-traefik.log
Reverse proxy system used to capture the communication to and from the system
/services-logs/kube-system/etcd/etcd.log
Access log for the etcd database. Authentication logs for the core system
/var/log/auth.log /var/log/deploy.log
Check for any problems that occurred during the deployment of the VA
# auth.log and deploy.log location
1. auth.log
/var/log/auth.log
2. deploy.log
/var/log/deploy.log
# Get the other required prelude logs
kubectl -n prelude logs {pod name} -n {namespace}
Monitoring Requests
To monitor all the requests through the web portal, navigate to Infrastructure > Activity > Requests
The Requests page displays the status of your services requests. If a failure occurs, you can start troubleshooting by viewing the failed request error.
vRealize Suite Integration
vRealize Log Insight - Integration
vRealize Automation is bundled with a fluentd-based logging agent. This agent collects and stores logs so that they can be included in a log bundle and examined later. You can configure this agent to forward a copy of the logs to a vRealize Log Insight server by using the vRealize Log Insight REST API.
You can forward logs from vRealize Automation to vRealize Log Insight to take advantage of robust log analysis and report generation. This integration is configured from an SSH session by using the vracli command set.
# Verify vRA integration with vRLI
vracli vrli # Verify output to see whether vRA has configured integration with vRLI
#How to forward logs from vRA to vRealize Log Insight (vRLI)
1. SSH to vRA appliance
2. Run command
vracli vrli set <logInsight_FQDN>
Port 9543 and https are used by default for sending the logs, but a different host scheme and port can be used. To configure http and a specific port, use the vracli command
vracli vrli set http://<vRealize_log_insight_FQDN>:<port>
You can check the existing configuration of vRealize Log Insight by using the vracli vrli command.
vRealize Log Insight: Interactive Analytics
vRealize Log Insight Interactive Analytics provides excellent diagnostic information for troubleshooting vRealize Automation. Administrators can set up log reviews live over more than one container, service, or even different endpoints by using various automatically built tags.
Multiple options exist for an enhanced log analysis:
- Timeframe: For specifying the time of logs. The available options are last hour, 6 hours, and a custom time range.
- Tags can be selected on the right under fields, or by + ADD FILTER. You can add more than one container service to look at multiple logs at once in the primary events window. You can select any or all options.
- Adding text examples with error allows the filtering of base text for rapid selections.
Selections can be saved as dashboards for rapid views and overviews of an environment. For more insights about your vRealize Automation appliance, you can download the vRealize Automation content pack from VMware Marketplace. Content packs contain dashboards, extracted fields, saved queries, and alerts that are related to a specific product or set of logs.
The vRealize Automation content pack is not mandatory for the integration.
vRealize Operations Manager
VMware vRealize Operations Manager delivers self-driving IT operations management for private, hybrid, and multicloud environments in a unified, AI-powered platform.
Powered by Artificial Intelligence, vRealize Operations Manager provides a unified operations platform, delivers continuous performance optimization, efficient capacity and cost management, proactive planning, app-aware intelligent remediation, and integrated compliance.
Integration in vRealize Automation
To integrate vRealize Automation with vRealize Operations Manager
# How to integrate vRA with vRO
1. Login to vRA, click Cloud Assembly
2. Navigate to Infrastructure > Connections > Integrations
3. Click + ADD INTEGRATION
4. Click vRealize Operations Manager to configure this integration.
To add the integration in vRealize Automation, we need
a. the vRealize Operations Manager URL
https://operations-manager-IP-address-or-FQDN/suite-api
b. the login user name, and password.
c. After entering the values, click VALIDATE.
Integration in vRealize Operations Manager
To integrate vRealize Operations Manager with vRealize Automation
1. Login to vRealize Operations Manager
2. Navigate to Administration > Management > Integrations.
3. Click the dots to the right of VMware vRealize Automation 8.x
4. click Configure
To add the integration in vRealize Operations Manager, we need
a. the vRealize Automation FQDN or IP address
b. the login user name, and password.
c. After entering the values, click VALIDATE CONNECTION.
vRealize Operations Manager - Integration Benefits
The integration between vRealize Automation and vRealize Operations Manager is a two-way integration.
Both products must be integrated to work with the other and each integration gives you different additional functionality. vRealize Automation can work with vRealize Operations Manager to display pricing, provide deployment health and virtual machine metrics, and perform advanced workload placement.
The integration with vRealize Operations Manager made these costing data available to vRealize Automation.
Integration Benefits - Deployment Monitoring
vRealize Automation retrieves vRealize Operations Manager metrics about your deployments.
# How to access deployment monitoring
1. Login to vRealize Automation -> Cloud Assembly
2. Click Deployables tab, and select a deployment
3. At the deployment window, select the Monitor tab
4. To see metrics, expand the component tree on the left, and highlight a virtual machine
The Metric tab appears only after configuring the integration with vRealize Operations Manager.
Metrics are not cached. vRealize Operations Manager provides the metrics directly and the metrics might take a few moments to load. Only virtual machine metrics appear.
Metrics appear as timeline graphs that show highs and lows for the following measures
1. CPU
2. Memory
3. Storage IOPS
4. Network MBPS
Integration Benefits - Workload Placement
After integrating with vRealize Operation Manager, a new placement policy appears under the Cloud Zones configuration.
# Configure cloud zone placement policy
1. Login to vRealize Automation -> cloud Assembly
2. Select Infrastructure tab
3. Expand Configure -> cloud Zone
4. Select the cloud zone, under Placement policy
a. DEFAULT
b. BINPACK
c. SPREAD
d. ADVANCED
This Advanced Placement Policy places workloads based on vRealize Operations Manager recommendations
vRealize Operations Manager considers operational intent for an optimal placement. Operational intent can take past workloads and future what-if predictions into account.
Operational and Troubleshooting
Shutdown vRealize Automation appliance properly, ssh to vRA appliance, run the following commands
1. /opt/scripts/svc-stop.sh
2. sleep 120
3. /opt/scripts/deploy.sh --onlyClean
4. shutdown
vRealize Orchestrator Control Center
with stanalone vRealize Orchestrator, we access the vRO Control Center from UI
1. Access vRO Control Center UI
https://<vRO-FQDN>/vco-controlcenter
2. login as root
How to configure standalone vRO with vRA autentication
To prepare the vRealize Orchestrator Appliance for use, you must configure the host settings and the authentication provider. You can configure vRealize Orchestrator to authenticate with vRealize Automation.
Important:
The product version of the vRealize Automation authentication provider must match the product version your vRealize Orchestrator deployment.
For example, to authenticate a vRealize Orchestrator 8.6 deployment, you must use a vRealize Automation 8.6 deployment.
# Procedure
1. Access the Control Center to start the configuration wizard
a. Navigate to https://your_orchestrator_FQDN/vco-controlcenter
b. Log in as root with the password you entered during OVA deployment
2. Configure the authentication provider
a. On the Configure Authentication Provider page,
select vRealize Automation from the Authentication mode drop-down menu.
b. In the Host address text box,
enter your vRealize Automation host address and click CONNECT
c. The format of the vRealize Automation host address must be
https:// your_vra_hostname
d. Click Accept Certificate
e. Enter the credentials of the vRealize Automation organization owner under which vRealize Orchestrator will be configured.
f. Click REGISTER
h. Click SAVE CHANGES.
A message indicates that your configuration is saved successfully
Upgrade vRealize Automation 8.x with vRealize Suite Lifecycle Manager
Prerequisites
- Ensure that you have upgraded the earlier versions of vRealize Suite Lifecycle Manager to the latest. For more information on upgrading your vRealize Suite Lifecycle Manager, see Upgrade vRealize Suite Lifecycle Manager 8.x.
- Ensure that you have upgraded the earlier version of VMware Identity Manager to 3.3.2 or later. For more information on VMware Identity Manager upgrade, see Upgrade VMware Identity Manager.
- Verify that you have already installed vRealize Automation 8.0, 8.0.1, 8.1, 8.2, or 8.3.
- Perform the binary mapping of the vRealize Automation upgrade ISO from Local, myvmware or NFS share. For more information on binary mapping, see Configure Product Binaries.
- Increase the CPU, memory, and storage as per the system requirements of vRealize Automation 8.4. For more information, see the Hardware Requirements of vRealize Automation 8.4 Reference Architecture.
Procedure
- On the Lifecycle Operations page, click Manage Environments.
- Navigate to a vRealize Automation instance.
- Click View Details and click Upgrade.
Note: A pop-up menu is appears to alert you to perform an inventory sync.
- Click Trigger Inventory Sync of the product before you upgrade.
Note:
At times, there can be a drift or a change in the environment outside of Lifecycle Manager and
for Lifecycle Manager to be aware of the current state of the system, the inventory requires to be up-to-date.
If the product inventory is already synced and up-to-date, then click Proceed Upgrade.
- After the inventory is synced, select the vRealize Automation version to 8.4.
- To select the Repository Type, you can either select vRealize Suite LCM Repository, only if you have mapped the ISO Binary map, or you can select the Repository URL with a private upgrade Repository URL.
- If you selected the Repository URL, enter the unauthenticated URL, and then click Next.
- Click Pre-Check.
- After passed all the pre-check, click Next and Submit
vRealize Automation Logs
tail -f /opt/vmware/log/vami/vami.log
Resize log partition
varcli disk-mgr resize
resize2fs /dev/mapper/logs_vg-log
Shutdown vRA
Log in to the console of any vRealize Automation appliance using either SSH or VMRC. To shut down the vRealize Automation services on all cluster nodes, Run the following set of commands. Note: If you copy any of these commands to run and they fail, paste them into notepad first, and then copy them again before running them. This procedure strips out any hidden characters and other artifacts that might exist in the documentation source.
/opt/scripts/deploy.sh --shutdown
Shut down the vRealize Automation appliances.
Your vRealize Automation deployment is now shut down.
Start vRealize Automation
Power on all vRealize Automation appliances and wait for them to start. Log into the console for any appliance using SSH or VMRC and run the following command to restore the services on all nodes.
/opt/scripts/deploy.sh
Verify that all services are up and running with the following command.
kubectl get pods --all-namespaces
Run the following command to verify that all services are running:
kubectl -n prelude get pods
Resize the vRA/vRO Log Disk
At first, I did remove some of the older log files that were occupying a lot of space (i.e. the very large log files). This did resolve the issue (once I have cleanly shutdown and rebooted). However, I didn’t want this to happen again, so I decided to investigate enlarging the volume. I found a useful article that outlined the approach.
Use vSphere to expand the VMDK on the vRealize Automation appliance. Log in to the command line of the vRealize Automation appliance as a root user, either through the console or ssh From the command prompt, run the following vRealize Automation command: vracli disk-mgr resize
vracli disk-mgr resize
Logs to check during an upgrade
These are a few logs which can be monitored or involved during the upgrade
The order of the logs is not the way it's being upgraded
/var/log/vmware/prelude/upgrade-YYYY-MM-DD-HH-NN-SS.log
/var/log/vmware/prelude/upgrade-report-latest
/var/log/vmware/prelude/upgrade-report-latest.json
/var/log/deploy.log
/opt/vmware/var/log/vami/vami.log
/opt/vmware/var/log/vami/updatecli.log
VMware vRealize Automation 8.0 Logs
https://www.stevenbright.com/2020/01/vmware-vrealize-automation-8-0-logs/
Resizing vRA/vRO logs disk (/dev/sdc) is not reflected in the OS (79925)
https://kb.vmware.com/s/article/79925
After increasing the size of the logs disk (/dev/sdc) of a vRealize Automation (vRA) or vRealize Orchestrator Appliance (vRO) appliance, and running "vracli disk-mgr resize", the new space is not reflected by OS. Running "vracli disk-mgr" or "df" commands still displays the old overall size.